Технологические вопросы крупных решений
21.02.2023
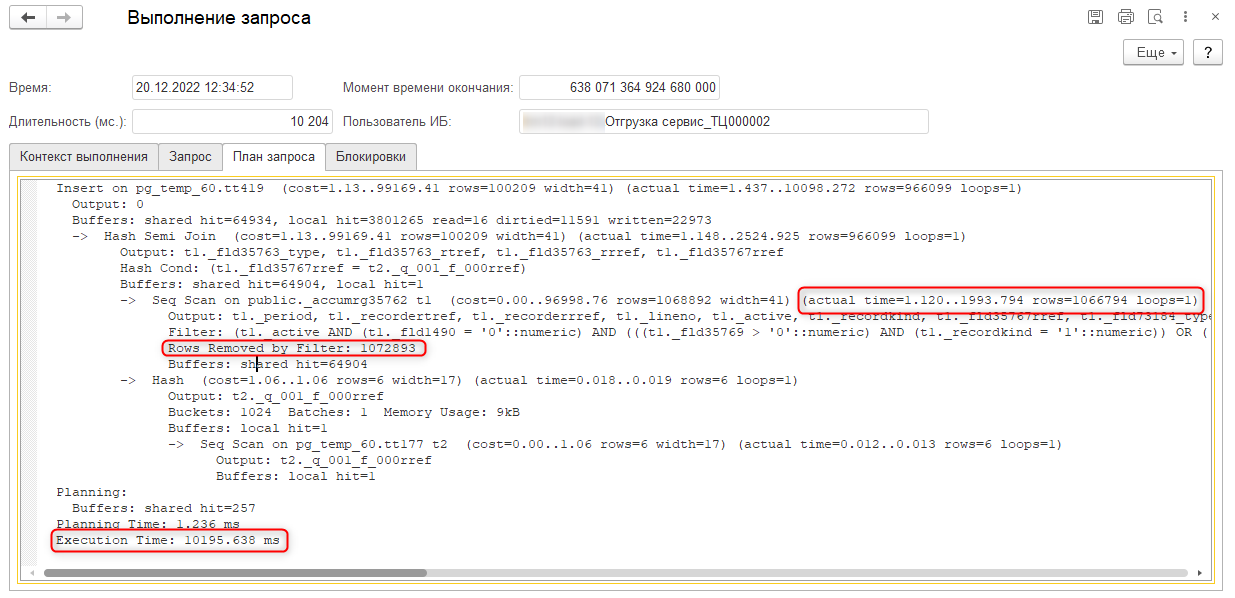
Для того чтобы быстро оценить влияние запросов на общее время работы, можно собрать технологический журнал с настройкой.
<log location="/var/logs/all_mini" history="8"> <event> <ne property="Name" value=""/> </event> </log>
(без тэга property)
Копировать в буфер обмена$ cat rphost_*/*.log | awk -F\- '{print $2}' | awk -F\, '{sum[$2]+=$1;} END {for (event in sum) print event" - "sum[event];}' DBPOSTGRS - 22189998668 CALL - 33908470608 TLOCK - 114341600 ... DBPOSTGRS / CALL = ~0,65
Соотношение суммарного времени DBPOSTGRS к CALL показывает объем времени, занимаемого запросами, в общем времени вызовов.
Если доля превышает примерно 50%, то это повод разбираться со скоростью выполнения запросов.
Для того, чтобы получить запрос и его план, необходимо настроить сбор технологического журнала. Пример настройки:
Копировать в буфер обмена<?xml version="1.0"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<log location="/var/log/srv1cv83" history="4">
<event>
<eq property="Name" value="DBPOSTGRS"/>
</event>
<property name="all"/>
</log>
</config>
ВНИМАНИЕ! Данный журнал может занимать значительный объем места на диске.
Настройку <plansql/> нельзя использовать на продуктивных серверах.
Только на серверах тестирования или разработки.
Чтобы получить план запроса, необходимо выполнить запрос непосредственно на сервере PostgreSQL с командой EXPLAIN.
Надо учитывать, что платформа «1С:Предприятие» устанавливает собственные параметры соединения с PostgreSQL. Их также необходимо установить перед выполнением запроса.
Рекомендуется создать файл с необходимыми командами и текстами запросов. Затем выполнить его из командной строки, перенаправив вывод в файл на диске.
Например, есть событие DBPOSTGRS из технологического журнала:
Копировать в буфер обмена38:31.223006-1,DBPOSTGRS,5,process=rphost,p:processName=DATABASE,...,SessionID=2,...,dbpid=11988,Sql="SELECT T1._IDRRef, T1._Number, T1._Date_Time, T1._Fld30743RRef FROM _Document1337 T1 WHERE ((T1._Fld2830 = CAST(0 AS NUMERIC))) AND (T1._IDRRef = '\\200\\310p\\213\\315U\\034~\\021\\347\\025\\340@\\243\\3650'::bytea)",RowsAffected=1,Result=PGRES_TUPLES_OK,Context='Форма.Вызов : ВыполнитьЗапросСервер…
Создать файл с запросом:
Копировать в буфер обмена$ vim query.sqlКопировать в буфер обмена
/* Параметры соединения платформы */ SET client_min_messages=error; SET lc_messages to 'en_US.UTF-8'; SET enable_mergejoin = off; SET escape_string_warning = off; SET cpu_operator_cost = 0.001; set client_encoding = 'utf8'; SET lock_timeout = 20000; EXPLAIN ANALYZE VERBOSE -- Получение актуального плана запроса SELECT T1._IDRRef, T1._Number, T1._Date_Time, T1._Fld30743RRef FROM _Document1337 T1 WHERE ((T1._Fld2830 = CAST(0 AS NUMERIC))) AND (T1._IDRRef = '\\200\\310p\\213\\315U\\034~\\021\\347\\025\\340@\\243\\3650'::bytea)
Выполнение:
Копировать в буфер обмена$ psql -U postgres --dbname=DATABASE --file=query.sql > query.sqlplan
Будет получен актуальный план запроса, идентичный платформенному.
Копировать в буфер обмена
$ cat query.sqlplanКопировать в буфер обмена
Index Scan using _document1337_s_hpk on public._document1337 t1 (cost=0.06..8.07 rows=1 width=69) (actual time=0.011..0.011 rows=0 loops=1) Output: _idrref, _number, _date_time, _fld30743rref Index Cond: ((t1._fld2830 = '0'::numeric) AND (t1._idrref = '\x5c3230305c333130705c3231335c333135555c3033347e5c3032315c3334375c3032355c333430405c3234335c33363530'::bytea)) Planning Time: 2.585 ms Execution Time: 0.069 ms (5 rows)
Сложности возникают, когда исследуемый запрос использует временные таблицы. Тогда, необходимо собрать все запросы, которые заполняют эти таблицы (вверх по журналу от исследуемого запроса).
Копировать в буфер обмена
$ vim query.sql
Копировать в буфер обмена
SET client_min_messages=error;
SET lc_messages to 'en_US.UTF-8';
SET enable_mergejoin = off;
SET escape_string_warning = off;
SET cpu_operator_cost = 0.001;
set client_encoding = 'utf8';
SET lock_timeout = 20000;
-- запрос использует временную таблицу, необходимо ее создать и заполнить перед его выполнением
drop table if exists tt7 cascade;
create temporary table tt7 (_Q_000_F_000RRef bytea ) without oids;
drop index if exists tmpind_0;
create index tmpind_0 on pg_temp.tt7(_Q_000_F_000RRef);
INSERT INTO pg_temp.tt7 (_Q_000_F_000RRef) SELECT
T1._IDRRef
FROM _Document1017 T1
WHERE (T1._Fld2830 = CAST(0 AS NUMERIC))
;
ANALYZE pg_temp.tt7;
EXPLAIN ANALYZE VERBOSE -- Получение актуального плана запроса
SELECT
(T1._Fld30691_TYPE || T1._Fld30691_RTRef),
T1._IDRRef
FROM _Document1337 T1
INNER JOIN pg_temp.tt7 T2 -- временная таблица
ON ('\\010'::bytea = T1._Fld30691_TYPE AND '\\000\\000\\003\\371'::bytea = T1._Fld30691_RTRef AND T2._Q_000_F_000RRef = T1._Fld30691_RRRef)
WHERE ((T1._Fld2830 = CAST(0 AS NUMERIC))) AND ((((T1._Fld30691_TYPE || T1._Fld30691_RTRef) <> '\\010\\000\\000\\004\\021'::bytea)))
Чтобы не собирать всю цепочку запросов вручную можно воспользоваться скриптом на языке 1С-Исполнитель getPGQueryWithTempTables.sbsl. После выполнения скрипт создаст файл (или выведет информацию в консоль), где соберет всю цепочку временных таблиц, необходимых для выполнения запроса.
Иногда необходимо передать разработчику «плохой» запрос и данные (для его выполнения), чтобы можно было воспроизвести проблему на другом сервере (например, под отладкой).
Передача всей базы данных затруднительна или невозможна.
Можно выгрузить только требуемые таблицы. Например, сам запрос и все временные таблицы строятся из таблиц _AccumRg1, _Reference2, _Reference3.
Копировать в буфер обмена
$ pg_dump -h server -U postgres -Fp -b -v -t _AccumRg1 -t _Reference2 -t _Reference3 -d ИМЯБАЗЫ -f /tmp/tables.backup
Однако, если цепочка временных таблиц слишком большая, или текст запроса содержит большое число таблиц, то проще получить их список с помощью скрипта. Для этого, необходимо взять файл с текстом «плохого» запроса и подготовкой всех временных таблиц, для его исполнения. А затем, выполнить скрипт:
Копировать в буфер обмена
$ cat bad_query.sql | grep -oP "(^|\s)_[a-zA-Z]+[0-9]+(_[a-zA-Z0-9]+)?" | grep -vP '^\s+_Fld.*' | grep -vP "_LineNo[0-9]+" | sort | uniq | tr -s '\n' '$' | sed 's/ //g' | sed 's/$$//' | sed 's/\$/ -t /g' | sed 's/\$$//g' | xargs -i echo pg_dump -h server -U postgres -Fp -O -t '{}' -f tables.backup [имя_базы]
Скрипт выведет текст команды pg_dump, для получения только необходимых данных.
Если, для сбора текста запроса, пользоваться скриптом getPGQueryWithTempTables.sbsl, то текст команды pg_dump будет в конце сформированного файла (или вывода консоли).
Для того, чтобы загрузить выгруженные таблицы в новую базу, необходимо создать новую базу на postgres с помощью 1С-Предприятия. В противном случае, будет ошибка при восстановлении таблиц из бэкапа.
Копировать в буфер обмена
$ /opt/1cv8/e2k/8.3.22.1851/1cv8 CREATEINFOBASE Srvr=server\;Ref=ИМЯБАЗЫ\;SchJobDn=Y\;SQLSrvr=СЕРВЕРБД\;DBMS=PostgreSQL\;DB=ИМЯБАЗЫ\;DBUID=postgres\;DBPwd=postgres\;CrSQLDB=Y\; $ psql -h server -U postgres -d ИМЯБАЗЫ -1 -f /tmp/tables.backup -v ON_ERROR_STOP=1
Если необходимо выгрузить базу данных 1С:Предприятия, которая содержит:
То необходимо сначала выгрузить схему данных:
Копировать в буфер обмена$ pg_dump -h server -U postgres --schema-only --dbname=ИМЯБАЗЫ --format=p > schema.sql
Затем, выгрузить данные необходимых таблиц.
Копировать в буфер обмена$ pg_dump -h server -U postgres --format=p -b --dbname=ИМЯБАЗЫ --clean --if-exists -t _YearOffset -t Config -t ConfigCAS -t ConfigCASSave -t ConfigSave -t DBSchema -t DepotFiles -t Files -t IBVersion -t Params -t SchemaStorage | sed '/^users[.]usr/d' > data.sql
Восстановление базы выполняется в два шага:
Копировать в буфер обмена$ psql -h server -U postgres --dbname=ИМЯБАЗЫ < schema.sqlКопировать в буфер обмена$ psql -h server -U postgres --dbname=ИМЯБАЗЫ < data.sql
Если необходимо выгрузить полностью базу в простом формате, не разбивая на схему и данные, то это можно сделать так:
Копировать в буфер обмена$ pg_dump -h server -U postgres -d ИМЯБАЗЫ-f database.sql -Fp
Восстановление базы выполняется в один шаг:
$ psql -U postgres -h server -d ИМЯБАЗЫ -f database.sql
Иногда бывает полезным выполнить загрузку в одной транзакции и с контролем наличия ошибок. Тогда будет остановка при первой ошибке:
Копировать в буфер обмена$ psql -U postgres -h server -d ИМЯБАЗЫ -1 -f database.sql -v ON_ERROR_STOP=1
Запросы можно собирать непосредственно в журнале PosgreSQL.
Копировать в буфер обмена
$ psql
ALTER SYSTEM SET lc_messages = 'C'; -- все сообщения на английском языке
ALTER SYSTEM SET logging_collector = on; -- потребуется перезапуск сервера
ALTER SYSTEM SET log_directory = 'log';
ALTER SYSTEM SET log_min_duration_statement = 0; -- 0-все запросы. ВНИМАНИЕ. Сбор всех запросов может ухудшить производительность при высокой нагрузке.
ALTER SYSTEM SET log_duration = on;
Копировать в буфер обмена
$ перезапуск кластера любым способом (pg_ctl / pg_ctlcluster / systemd / service / ...)
После этого в каталоге кластера, в папке «log», появится текстовый файл, который будет содержать в себе запросы PostgreSQL.
Преобразование журнала PostgreSQL к однострочному формату (каждое событие в одной строке):
Копировать в буфер обмена$ cat postgresql.log | awk -vORS= '{if(match($0, "^[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9] ")) print "\n"$0; else print "<line>"$0;}'
Бывает, необходимо получать планы запросов в логе postgres. Например, при вставке во временную таблицу из таблицы значений, используется конструкция COPY … FROM STDIN.
Данные, которые вставляются во временную таблицу, нигде не логируются. Поэтому, сбор цепочки запросов по технологическому журналу не даст эффекта.
Копировать в буфер обмена
$ psql
Получить значение настройки shared_preload_libraries .
Копировать в буфер обменаSELECT current_setting('shared_preload_libraries');
Дописать модуль auto_explain (потребуется перезапуска кластера).
Копировать в буфер обменаALTER SYSTEM SET shared_preload_libraries = '<модуль1>', '<модуль2>',…, 'auto_explain';
перезапуск кластера
Копировать в буфер обмена
$ psql
Настройки модуля auto_explain
Копировать в буфер обменаALTER SYSTEM SET auto_explain.log_min_duration = '10s'; -- записывать в лог план для запросов >= 10 сек.
ALTER SYSTEM SET auto_explain.log_analyze = true;
SELECT pg_reload_conf(); -- применение настроек
ВНИМАНИЕ! Автоматическое построение планов запросов снижает производительность системы.
Поэтому необходимо задавать параметр auto_explain.log_min_duration, получая планы только длительных запросов.
Для получения более детальной информации о работе PostgreSQL можно включить сбор отладочных логов.
Копировать в буфер обмена
$ psql
ALTER SYSTEM SET log_min_messages = 'debug2'; -- debug1...debug5
SELECT pg_reload_conf(); -- применение настроек
ВНИМАНИЕ! Включение данного журнала будет занимать значительный объем и может привести к замедлению СУБД.
Для расследования проблем может понадобится статистика по потреблению ресурсов запросами:
Для этого необходимо подключить модуль pg_stat_statements.
Копировать в буфер обмена$ psql
ALTER SYSTEM SET shared_preload_libraries = …, 'auto_explain', 'pg_stat_statements';
перезапуск кластера
Копировать в буфер обмена
$ psql ALTER SYSTEM SET pg_stat_statements.max = 10000; ALTER SYSTEM SET pg_stat_statements.track = 'all'; SELECT pg_reload_conf(); -- применение настроек \с ИМЯ _БАЗЫ CREATE EXTENSION pg_stat_statements; SELECT pg_stat_statements_reset(); -- для сброса накопленной статистики..
Подробное описание pg_stat_statements см. https://www.postgresql.org/docs/current/pgstatstatements.html
-- Нагрузка, создаваемая запросами SELECT pg_database.datname AS Database, pg_stat_statements.query AS Query, pg_stat_statements.calls AS ExecutionCount, pg_stat_statements.total_exec_time ExecutionTime, pg_stat_statements.shared_blks_read + pg_stat_statements.shared_blks_written AS Memory, pg_stat_statements.local_blks_read + pg_stat_statements.local_blks_written AS IO, pg_stat_statements.temp_blks_read + pg_stat_statements.temp_blks_written AS Temp FROM pg_stat_statements AS pg_stat_statements INNER JOIN pg_database AS pg_database ON pg_database.oid = pg_stat_statements.dbid ORDER BY ExecutionTime DESC
Копировать в буфер обмена
-- Процент попадания в кэш SELECT round(100 * sum(blks_hit) / sum(blks_hit + blks_read), 3) as cache_hit_ratio FROM pg_stat_database;
Копировать в буфер обмена
-- Размер таблиц и индексов SELECT t.tablename, indexname, c.reltuples::integer AS num_rows, pg_size_pretty(pg_relation_size(quote_ident(t.tablename)::text)) AS table_size, pg_size_pretty(pg_relation_size(quote_ident(indexrelname)::text)) AS index_size, CASE WHEN x.is_unique = 1 THEN 'Y' ELSE 'N' END AS UNIQUE, idx_scan AS number_of_scans, idx_tup_read AS tuples_read, idx_tup_fetch AS tuples_fetched FROM pg_tables t LEFT OUTER JOIN pg_class c ON t.tablename=c.relname LEFT OUTER JOIN (SELECT indrelid, max(CAST(indisunique AS integer)) AS is_unique FROM pg_index GROUP BY indrelid) x ON c.oid = x.indrelid LEFT OUTER JOIN ( SELECT c.relname AS ctablename, ipg.relname AS indexname, x.indnatts AS number_of_columns, idx_scan, idx_tup_read, idx_tup_fetch,indexrelname FROM pg_index x JOIN pg_class c ON c.oid = x.indrelid JOIN pg_class ipg ON ipg.oid = x.indexrelid JOIN pg_stat_all_indexes psai ON x.indexrelid = psai.indexrelid ) AS foo ON t.tablename = foo.ctablename WHERE t.schemaname='public' ORDER BY pg_relation_size(quote_ident(indexrelname)::text) desc;
Копировать в буфер обмена
-- Отсутствие индексов SELECT relname, seq_scan - coalesce(idx_scan, 0) AS too_much_seq, case when seq_scan - coalesce(idx_scan, 0) > 0 THEN 'Нет индекса?' ELSE 'OK' END AS Message, pg_relation_size(relname::regclass) AS rel_size, seq_scan, coalesce(idx_scan, 0) AS idx_scan FROM pg_stat_all_tables WHERE schemaname='public' AND pg_relation_size(relname::regclass)>10000 -- ограничение на размер анализируемых таблиц ORDER BY too_much_seq DESC;
Копировать в буфер обмена
-- Использование буферного КЭШа (необходимо установить расширение pg_buffercache)
CREATE EXTENSION pg_buffercache;
SELECT 'total', pg_size_pretty(count(*) * (SELECT current_setting('block_size')::int)) FROM pg_buffercache
UNION
SELECT 'dirty', pg_size_pretty(count(*) * (SELECT current_setting('block_size')::int)) FROM pg_buffercache WHERE isdirty
UNION
SELECT 'clear', pg_size_pretty(count(*) * (SELECT current_setting('block_size')::int)) FROM pg_buffercache WHERE NOT isdirty
UNION
SELECT 'used', pg_size_pretty(count(*) * (SELECT current_setting('block_size')::int)) FROM pg_buffercache WHERE reldatabase IS NOT NULL
UNION
SELECT 'free',pg_size_pretty(count(*) * (SELECT current_setting('block_size')::int)) FROM pg_buffercache WHERE reldatabase IS NULL
;
Копировать в буфер обмена
-- Содержимое буферного пула
SELECT
c.relname,
pg_size_pretty(pg_relation_size(c.oid)) as relation_size,
pg_size_pretty(count(b.bufferid) * (SELECT current_setting('block_size')::int)) AS buffered_in_shared_buffers,
round(100 * count(b.bufferid) * (SELECT current_setting('block_size')::int) / greatest(1,pg_relation_size(c.oid)),1) as pct_of_relation,
round((100 * count(b.bufferid) / greatest(1,(SELECT setting FROM pg_settings WHERE name = 'shared_buffers')::decimal)),2) AS pct_of_shared_buffers
FROM pg_class c
INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenode
AND b.reldatabase IN (0, (SELECT oid FROM pg_database WHERE datname = current_database()))
-- WHERE c.relname = 'products' AND usagecount >= 2 – если нужен отбор по таблице
GROUP BY c.oid, c.relname ORDER BY count(b.bufferid) * 8192 DESC LIMIT 10;
Требуется разовая настройка:
Копировать в буфер обмена$ psql
ALTER SYSTEM SET track_activity_query_size = 1048576; -- храним тексты запросов размером до 1Мб.
Далее перезапускаем кластер, чтобы настройка применилась.
Теперь можно выполнять запрос:
Копировать в буфер обмена
$ psql SELECT datname, application_name, pid, now() - pg_stat_activity.query_start AS duration, query FROM pg_stat_activity WHERE state = 'active' ORDER BY duration DESC LIMIT 10;
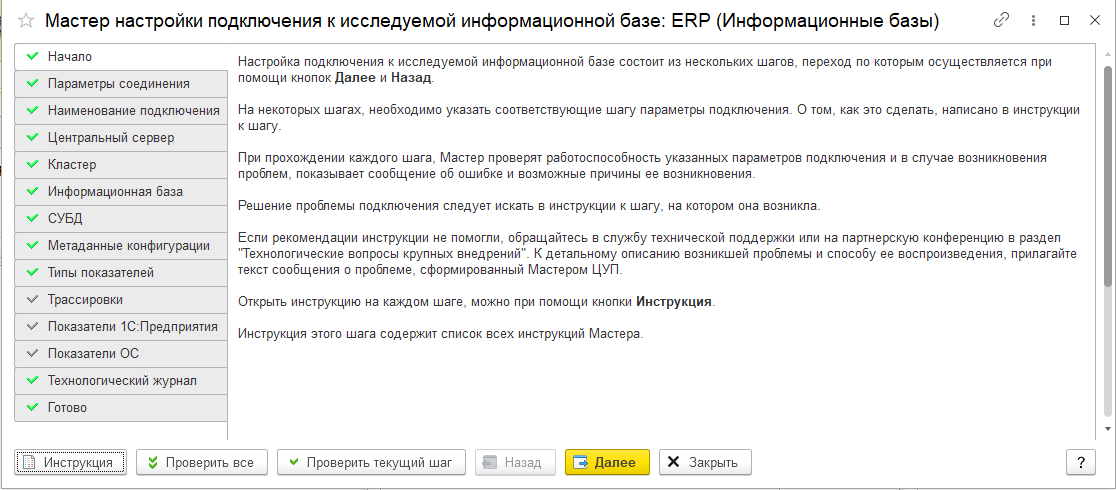
Для расследования долгих запросов можно воспользоваться конфигурацией «Центр управления производительностью» из «Корпоративного инструментального пакета».
Для этого необходимо подключить исследуемую базу в режиме мониторинга.
Снять замеры и выполнить анализ.
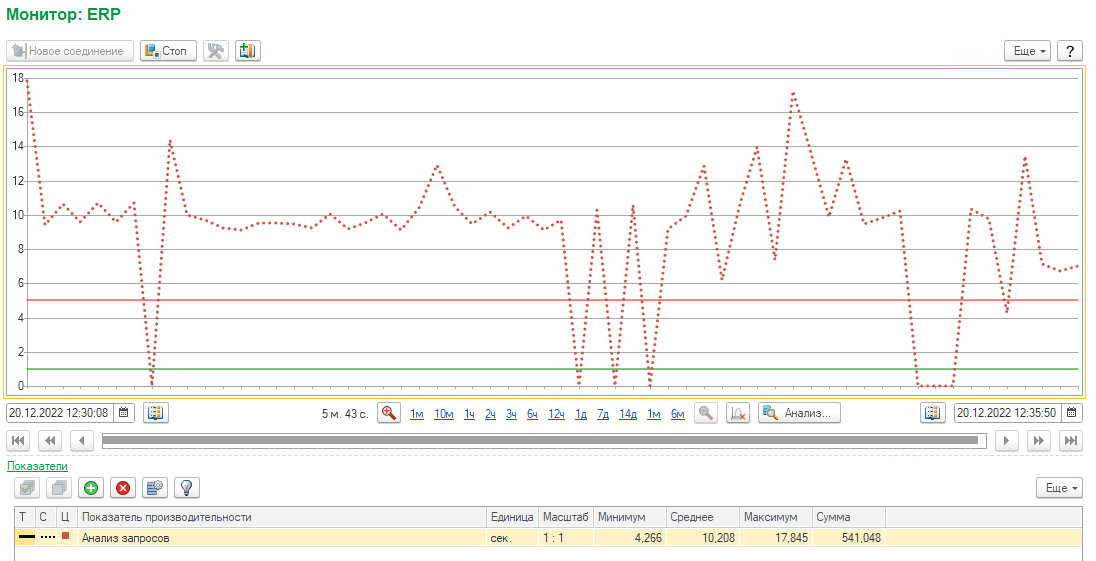
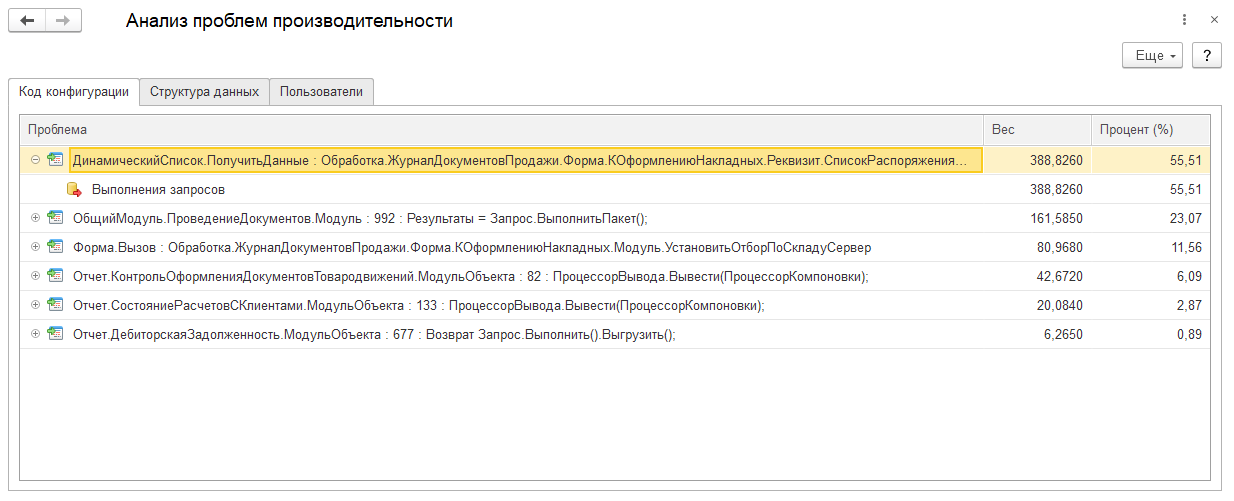
Если нет конкретного запроса, который приводит к замедлению системы (СУБД в целом работает медленно), то для расследования причин можно воспользоваться сбором статистики по ожиданиям.
Подробную информацию об ожиданиях см. https://www.postgresql.org/docs/current/monitoring-stats.html#MONITORING-PG-STAT-ACTIVITY-VIEW (в частности, см. описание полей «wait_event_type» и «wait_event»).
Простой скрипт мониторинга текущих ожиданий:
Копировать в буфер обмена$ vim ./wait_monitor.sh
#!/bin/bash
while true
do
printf "\033c"
psql -h server -U postgres -c "select wait_event_type, wait_event, count(*) as count from pg_stat_activity where state='active' group by wait_event_type, wait_event order by 3 desc;"
sleep 3
done
Копировать в буфер обмена
$ chmod +x ./wait_monitor.shКопировать в буфер обмена
$ ./wait_monitor.sh
Cкрипт можно запустить в отдельном окне терминала и наблюдать в режиме реального времени, статистику по ожиданиям.
Данная статистика приблизительная, т.к. на экран выводится состояние по ожиданиям раз в 3 секунды. Все, что произошло за 3 секунды паузы – теряется.
Но для общей картины происходящего этого достаточно.
Затем необходимо взять ожидание, которое чаще всего находится на самом верху и разобраться в его причинах, воспользовавшись его описанием по ссылке https://www.postgresql.org/docs/current/monitoring-stats.html#WAIT-EVENT-TABLE
Чтобы накапливать статистику по ожиданиям, можно сохранять вывод скрипта в файл.
Для этого скрипт необходимо модифицировать:
Копировать в буфер обмена
$ vim ./wait_monitor_csv.sh
#!/bin/bash
while true
do
psql -h server -U postgres --no-align --csv --tuples-only -c "select now() as timestamp, wait_event_type, wait_event, count(*) as count from pg_stat_activity where state='active' group by wait_event_type, wait_event;"
sleep 3
done
Копировать в буфер обмена
$ chmod +x ./wait_monitor_csv.shКопировать в буфер обмена
$ ./wait_monitor_csv.sh >> ./wait.log
В файл wait.log будут собраны снимки ожиданий.
Выполнить анализ собранных ожиданий можно с помощью psql.
Копировать в буфер обмена
$ psql
create temp table waits(timestamp timestamp, wait_event_type varchar(100), wait_event varchar(100), count int);
COPY pg_temp.waits(timestamp, wait_event_type, wait_event, count) FROM '/home/user/wait.log' DELIMITER ',' CSV;
SELECT wait_event_type, wait_event, SUM(count) FROM pg_temp.waits GROUP BY wait_event_type, wait_event ORDER BY 3 DESC;
Установка
Копировать в буфер обмена$ sudo apt install atop
Режим интерактивного мониторинга
Копировать в буфер обмена$ sudo atop
Cбор данных в файл. 1200 снимков с интервалом 3 секунды (1 час.)
Копировать в буфер обмена$ sudo atop -w atop.log 3 1200
Если запущена служба atop, то счетчики оборудования снимаются постоянно. См.
Копировать в буфер обмена$ sudo systemctl status atop
Loaded: loaded (/lib/systemd/system/atop.service; enabled; vendor preset: enabled)
. . . . . . .
CGroup: /system.slice/atop.service
??6984 /usr/bin/atop -R -w /var/log/atop/atop_20221220 600
600 – это количество секунд между снимком информации о загруженности оборудования.
Частоту снятия счетчиков, службой, можно поменять
Копировать в буфер обмена$ sudo vim /etc/default/atop
INTERVAl=60
Копировать в буфер обмена
$ sudo systemctl restart atop
Настройки журнала ежедневных счетчиков
Копировать в буфер обмена$ sudo vim /usr/share/atop/atop.daily
Сбор данных в формате, пригодном для автоматической обработки (раз в секунду, до остановки по Ctrl+C)
Копировать в буфер обмена$ sudo atop -P CPU,DSK,MEM,NET 1 > atop.csv
Преобразование бинарного файла в данные для автоматической обработки
Копировать в буфер обмена$ atop -r /var/log/atop/atop_20221221 -P CPU,DSK,MEM,NET > atop.csv
Преобразование бинарного файла в текстовое представление для просмотра
Копировать в буфер обмена$ atop -r /var/log/atop/atop_20221221 > atop.txt
Для визуализации atop можно написать «парсер», который преобразует собранные данные в формат (например csv).
Затем, загрузить эти данные в любое ПО для построения графиков.
Готовые средства, для просмотра графиков atop, можно найти в интернете по фразе «atop visualization».
Более продвинутое в визуальном смысле средство мониторинга - nmon.
Установка
Копировать в буфер обмена$ sudo apt install nmon
Режим интерактивного мониторинга
Копировать в буфер обмена$ sudo nmonКопировать в буфер обмена
## (нажать C n d t u)
Если запустить в отдельной консоли монитор ожиданий PostgreSQL, то можно оценивать текущее состояние postgres и загрузки сервера.
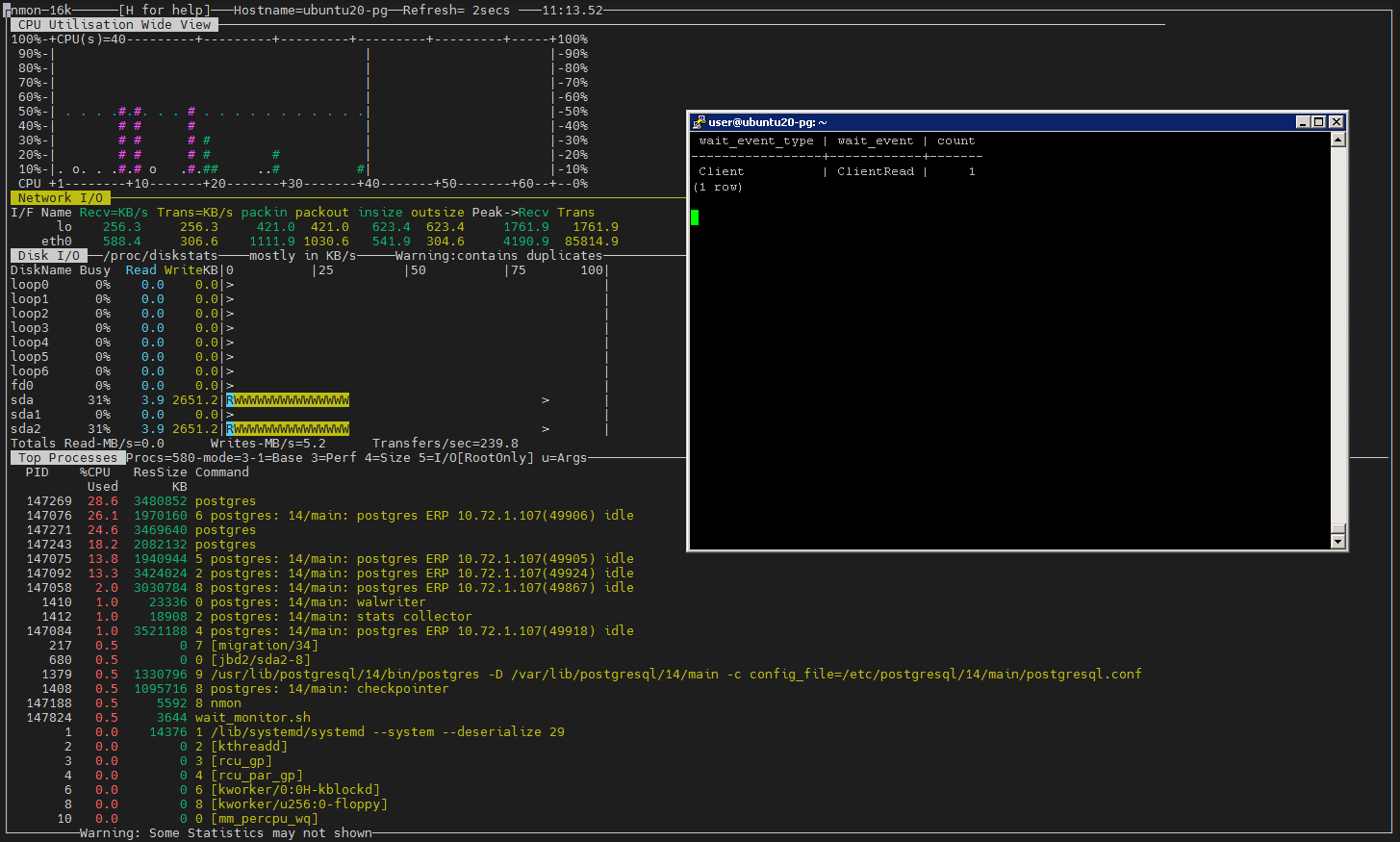
Cбор данных в файл
Копировать в буфер обмена$ nmon -f -s 2 -c 600 # 600 снимков с интервалом 2 секунды
Сформированный файл необходимо обработать для загрузки в ПО построения графиков.
Или воспользоваться готовыми средствами, которые можно найти по фразе «nmon visualizer».
Чтобы понять какой запрос нагружает оборудование, необходимо взять PID самого нагруженного процесса.

Найти его в технологическом журнале по полю dbpid.
53:32.515071-125295937,DBPOSTGRS,4,process=rphost,p:processName=erp,OSThread=42008,t:clientID=656,t:applicationName=1CV8C,t:computerName=server,t:connectID=13931,SessionID=190,
Usr=Кладовщик документы_ТЦ000018,AppID=1CV8C,DBMS=DBPOSTGRS,DataBase=127.0.0.1\ERP,Trans=0,dbpid=167172,Sql="
SELECT
T1._Fld836
FROM _InfoRg835 T1
LEFT OUTER JOIN _Document67 T2
ON T1._Fld847RRef = T2._IDRRef
WHERE (T1._Fld839RRef IN ( VALUES('\\257,\\260\\260w\\260\\347SFg\\321\\311\\271E\\225\\026'::bytea),
('\\215\\000\\001\\342cX\\242?B\\237\\321\\355\\002\\242\\210\\237'::bytea),
('\\265\\257\\323\\2650-\\274\\016Dp\\211\\263\\277\\376\\026\\012'::bytea)))
AND ((T1._Fld846 < '2022-11-21 00:00:00'::timestamp)
OR (T1._Fld847RRef <> '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea)
AND (T2._Date_Time IS NULL))
",RowsAffected=1,Result=PGRES_TUPLES_OK,Context='
Или в логе postgres
2022-12-21 09:53:32.121 MSK [167172] postgres@ERP LOG: duration: 1251.295 ms bind <unnamed>: SELECT
T1._Fld836
FROM _InfoRg835 T1
LEFT OUTER JOIN _Document67 T2
ON T1._Fld847RRef = T2._IDRRef
WHERE (T1._Fld839RRef IN ( VALUES('\\257,\\260\\260w\\260\\347SFg\\321\\311\\271E\\225\\026'::bytea),
('\\215\\000\\001\\342cX\\242?B\\237\\321\\355\\002\\242\\210\\237'::bytea),
('\\265\\257\\323\\2650-\\274\\016Dp\\211\\263\\277\\376\\026\\012'::bytea)))
AND ((T1._Fld846 < '2022-11-21 00:00:00'::timestamp)
OR (T1._Fld847RRef <> '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea)
AND (T2._Date_Time IS NULL))
Если запрос еще выполняется, то получить его из pg_stat_activity
Копировать в буфер обмена
$ psql
SELECT datname, application_name, pid, now() - pg_stat_activity.query_start AS duration, query FROM pg_stat_activity WHERE state = 'active' and pid = 167172;