Технологические вопросы крупных внедрений
16.11.2022
Данная методика применяется в следующих случаях:
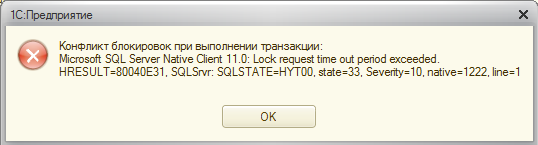
(рис.1. Пример ошибки конфликта блокировок)
Копировать в буфер обмена42:01.559001-0,EXCP,6,process=rphost,p:processName=test600,OSThread=6764,t:clientID=12,t:applicationName=1CV8C,t:computerName=Morozov-AN,t:connectID=4,SessionID=2,Usr=DefUser,AppID=1CV8C,dbpid=107,Exception=DataBaseException,Descr='Конфликт блокировок при выполнении транзакции: Microsoft SQL Server Native Client 11.0: Lock request time out period exceeded. HRESULT=80040E31, SQLSrvr: SQLSTATE=HYT00, state=33, Severity=10, native=1222, line=1 ',Context='Форма.Вызов : Обработка.Дедлоки.Форма.Форма.Модуль.ТаймаутСУБДНаСервере Обработка.Дедлоки.Форма.Форма.Форма : 267 : Реквизит1 = Спр.Реквизит1;'
Если вы видите колебание время выполнения операций, но до ошибок блокировок дело пока (или чаще всего) не доходит, необходимо убедиться, что дело касается очереди в результате ожидания на транзакционных блокировках.
Стоит учитывать, что колебания производительности должны быть воспроизводимы. Правильно сравнивать скорость выполнения одной и той же операции, убедившись, что
Естественно, ожидания на блокировках могут быть на различных данных в различных операциях ввиду пересечения на избыточных блокировках. Однако всё же каждая из этих операция может быть выполнена второй раз позднее на тех же данных за существенно меньшее время ввиду отсутствия одновременной с ней конкурирующей транзакции.
Какие (Где) ещё могут быть очереди:
Желательно на первом шаге убедиться, что ожидания не возникают на аппаратных ресурсах. Для этих целей можно использовать инструменты:
Мы не будем подробно останавливаться на этих инструментах, т.к. они не являются предметом этой методики.
На этом шаге также имеет смысл посмотреть с помощью strace (в Linux) или procmon (в Windows), нет ли колебаний производительности в результате каких-либо избыточных действий, которые могут проявить себя при рассмотрении системных вызовов (хотя чаще это просто не делают с надеждой, что тут все хорошо). Например, получить группировку по вызовам с помощью strace по процессам rphost можно таким образом:
for i in `pgrep rphost`; do echo "rphost " $i; time strace -r -f -p $i -e open,read,write,futex,stat,close,poll,lseek,openat,flock,recvfrom 2>&1 | head -n 100000 | sed -r 's/<\.\.\. //g' | sed -r 's/ resumed/_resumed/g' | sed -r 's/,? \".*\".*, /,{STR},/g' | sed -r 's/lseek\([0-9]+, [0-9]+, /lseek({NUM},{NUM},/g' | sed -r 's/, /,/g' | awk '{sum[$4]+=$3; count[$4]+=1;} END {for (i in sum) {if(sum[i]>0.0001) {print sum[i] " " count[i] " " i}}}' | sort -rnb | head; done
Эта методика в первом шаге содержит анализ загруженности оборудования для того, чтобы избавиться от сомнений, что проблема действительно в ожиданиях на блокировках. Однако не правильно ограничиваться проверкой загруженности оборудования только на первом шаге, т.к. в процессе устранения ожиданий на блокировках вырастет параллельность работы. Таким образом, ожидающие ранее транзакции будут выполняться, потребляя аппаратные ресурсы. В результате нагрузка на оборудование может значительно возрастать. Отслеживать отсутствие очередей на аппаратных ресурсах необходимо на всем протяжении работы. Но не стоит путать отслеживание наличия проблемы с правильной последовательностью устранения технологических проблем. Например, правильной последовательностью в процессе проведения нагрузочного тестирования и устранения проблем в нагрузочном тесте является:
Выяснить:
(Для упрощения понимания в этой статье термин "управляемые транзакционные блокировки" сокращается до "управляемые блокировки", а под термином "транзакционные блокировки" подразумеваются "транзакционные блокировки на СУБД". Естественно, блокировки на СУБД и управляемые блокировки в контексте данной статьи являются транзакционными.)
Проще всего проверить ожидание на управляемых блокировках. Если есть ошибка, которая свидетельствует, что проблема на уровне СУБД, то естественно можно расследовать именно её и пропустить шаг анализа проблем на управляемых блокировках. Но в общем случае ошибки может и не быть.
Для расследования ожиданий на управляемых блокировках потребуется либо настроить технологический журнал (logcfg.xml) вида
Копировать в буфер обмена
<?xml version="1.0" encoding="UTF-8"?> <config xmlns="http://v8.1c.ru/v8/tech-log"> <log location="G:\LOGS\TLOCK" history="2"> <event> <eq property="Name" value="TLOCK" /> </event> <event> <eq property="Name" value="TTIMEOUT" /> </event> <event> <eq property="Name" value="TDEADLOCK" /> </event> <event> <eq property="Name" value="SDBL" /> <eq property="Func" value="BeginTransaction" /> </event> <event> <eq property="Name" value="SDBL" /> <eq property="Func" value="RollbackTransaction" /> </event> <event> <eq property="Name" value="SDBL" /> <eq property="Func" value="CommitTransaction" /> </event> <property name="all" /> </log> </config>
либо в ЦУП (Центр Управления Производительностью, входящий в состав КИП (Корпоративного Инструментального Пакета)) добавить показатели сбора данных по ожиданиям на блокировках.
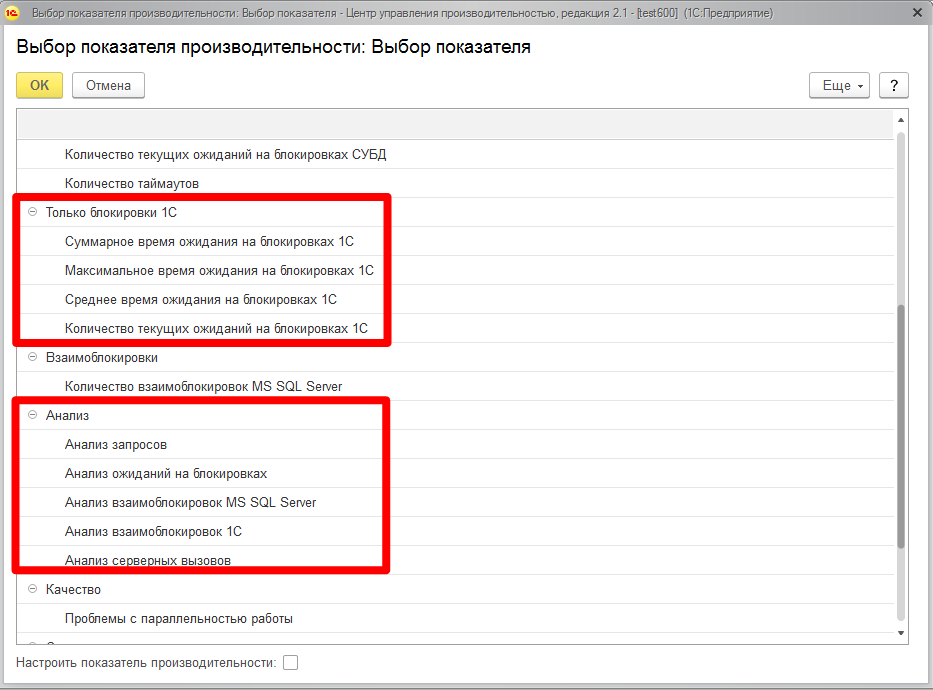
(рис.2. Выбор показателя производительности в ЦУП)
Лучше сразу добавить показатели из групп "Только блокировки 1С" и "Анализ":
В случае настройки (на этом шаге) технологического журнала вам в первую очередь потребуется найти события TLOCK с непустым полем WaitConnections, например:
Копировать в буфер обмена
21:01.456065-15,TLOCK,5,process=rphost,p:processName=test601_pmc,OSThread=8916,t:clientID=5,t:applicationName=1CV8C,t:computerName=Morozov-AN,t:connectID=2,SessionID=2,Usr=DefUser,AppID=1CV8C,Regions=InfoRg404.DIMS,Locks='InfoRg404.DIMS Exclusive Fld405=4216B7C0FEBDF74182BCEFF80930A8AD Fld406=51:ae237dae58d1d6c94b4e42c1ab63e0c1 Fld407=T"20180510092101" Fld408=00000000000000000000000000000000',WaitConnections=16,connectionID=82b7d8d9-c11e-47cd-937e-3984ff2177b3,Context='ОбщийМодуль.Вызов : ОбщийМодуль.ПоказателиПроизводительности.Модуль.ПолучитьСообщения ОбщийМодуль.ПоказателиПроизводительности.Модуль : 1994 : СообщениеМенеджерЗаписи.Удалить();'
В поле WaitConnections указывается номер t:connectID (идентификатора соединения, не изменяющегося в пределах транзакции), ожидание которого имело место при попытке установки управляемой блокировки.
Найти такие события можно, например, так:
Копировать в буфер обмена
grep -rP 'TLOCK.*WaitConnections=\d+'
Найти ожидания, которые, скорее всего, привели к таймаутам на управляемых блокировках, можно, например, так:
Копировать в буфер обмена
grep -rP '\d{6,},TLOCK.*WaitConnections=\d+'
Т.е. такие ожидания, которые выполнялись длительное время, однако нужно помнить, что максимальное время ожидания настраивается в конфигураторе в меню "Администрирование \ Параметры информационной базы \ Время ожидания блокировки данных (в секундах)".
Из текста события сразу становится понятно:
Далее потребуется найти в пределах транзакции (в примере настройки logcfg.xml выше указаны события SDBL относительно начала и окончания транзакции) события TLOCK с найденным t:connectID (т.е. WaitConnections=16) по тому же пространству. Например, это можно сделать так:
Копировать в буфер обмена
grep -rP 'TLOCK.*t:connectID=16,.*InfoRg404.DIMS.*Fld405=4216B7C0FEBDF74182BCEFF80930A8AD Fld406=51:ae237dae58d1d6c94b4e42c1ab63e0c1 Fld407=T"20180510092101" Fld408=00000000000000000000000000000000'
Следует разделять:
В ожидающей транзакции было затрачено ненулевое время на ожидание возможности установить блокировку (это касается и ожидания блокировок на уровне СУБД). В ожидаемой транзакции такое время могли и не тратить, т.е. блокировка могла установиться "сразу". По этой причине, не стоит искать блокировки ожидаемых (виновных) транзакций в журналах или трассировках, собранных с каким-либо ограничением по длительности, т.к. этих блокировок может там и не быть.
Лучше всего при расследовании помнить следующие правила:
По сути, вам потребуется:
В случае использования ЦУП расследование будет выполнено автоматически по ожиданиям на управляемых блокировках, а также по ожиданиям на транзакционных блокировках на СУБД. От вас не потребуется ничего, кроме как нажать кнопку "Анализ".
В случае нехватки времени или опыта рекомендуем использовать ЦУП.
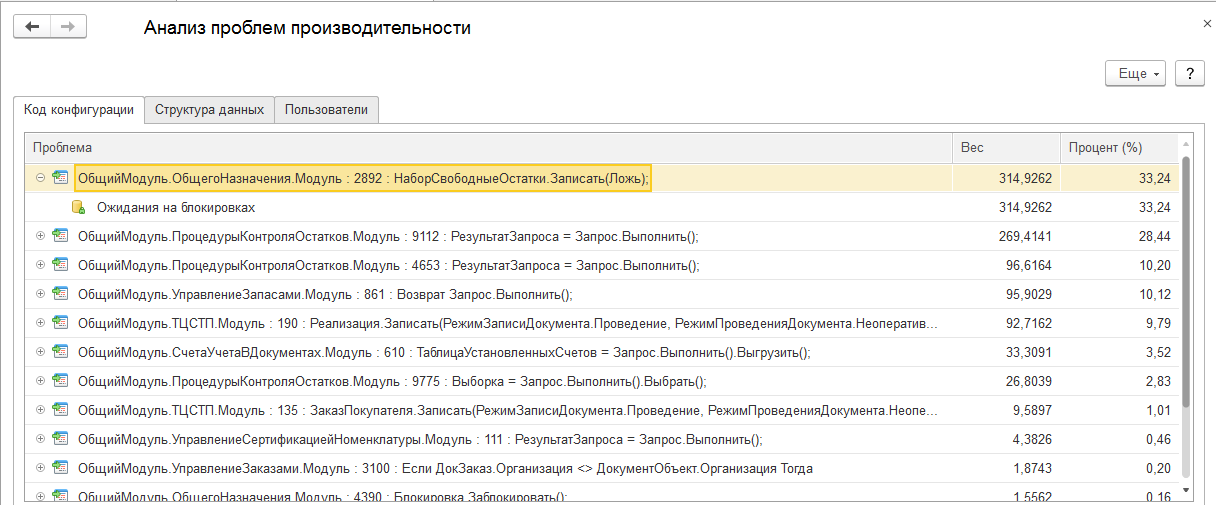
(рис.3. Анализ проблем производительности в ЦУП)
При выборе любой из строк группировки контекстов, вы сможете обнаружить детализацию по выявленным проблемам.
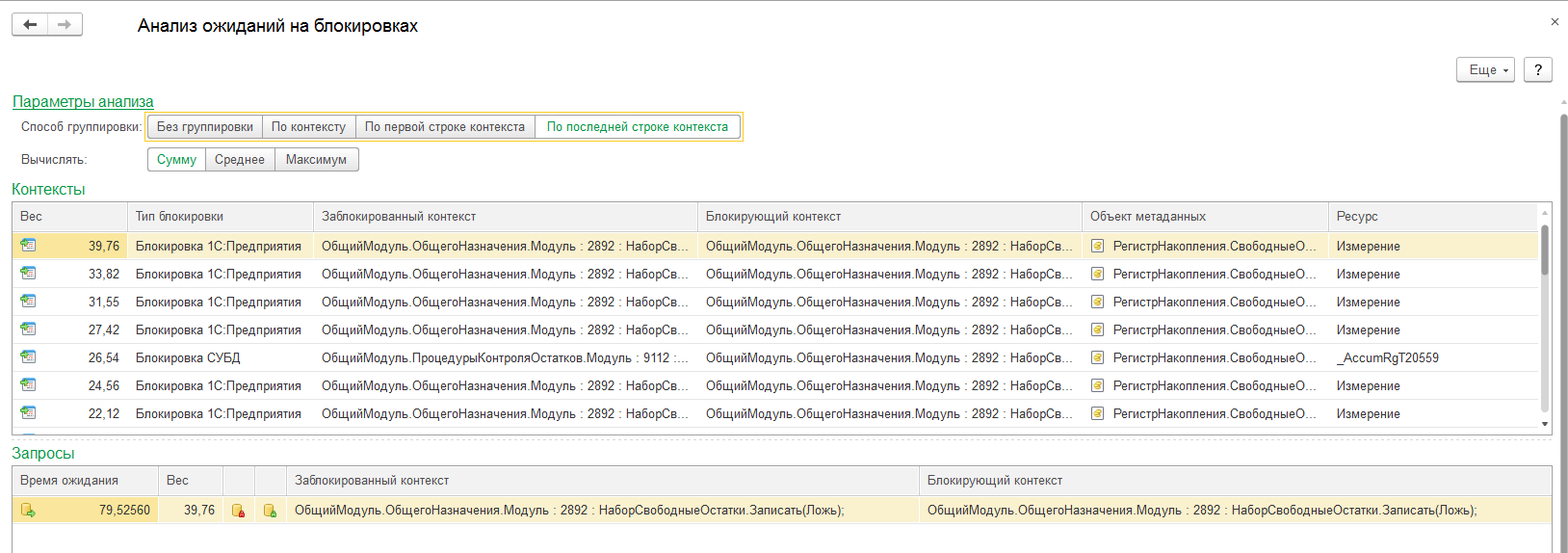
(рис.4. Анализ ожиданий на блокировках в ЦУП)
Выбрав, например, "Ресурс", вы сможете увидеть детализацию по всем полям, которые были указаны в блокировке.
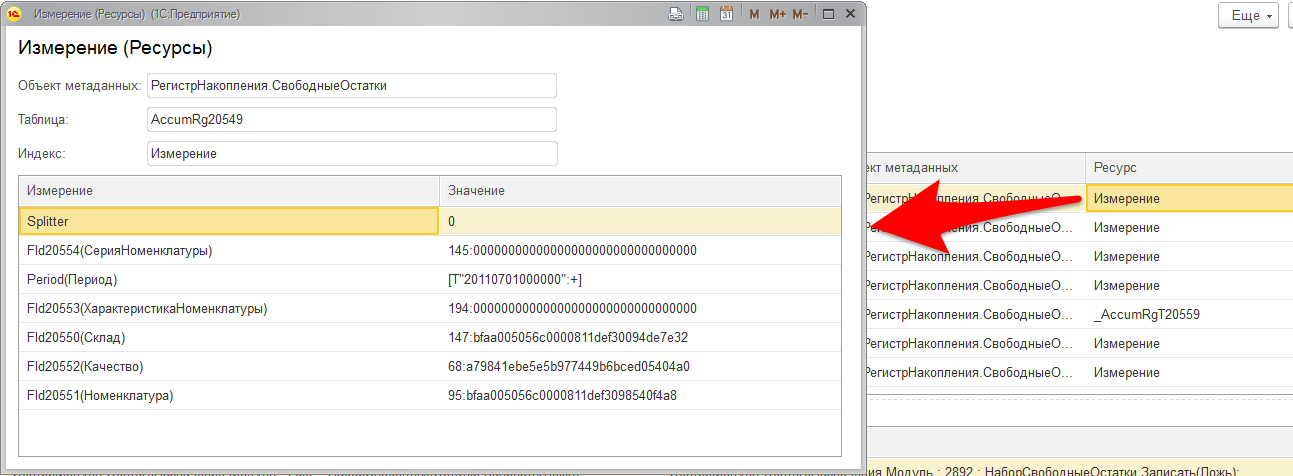
(рис.5. Детализация измерений управляемой блокировки в ЦУП)
Обращаем внимание, что вы сможете:
Допустим, мы не обнаружили на шаге 2 никаких ожиданий на управляемых транзакционных блокировках, которые могли бы составить искомое замедление скорости выполнения операции.
Таким образом, мы смотрим в сторону выполнения запросов в СУБД.
Время выполнения запросов с точки зрения платформы 1С:Предприятия 8 может изменяться:
Т.е. на этом шаге мы снова либо выполняем серьезное предположение, что дело именно в ожиданиях на транзакционных блокировках (например, потому что мы видели соответствующие ошибки в технологическом журнале), либо мы заранее исключили все другие варианты (ожидания на каких-либо других ресурсах). (Рассматриваем управляемый режим управления блокировками данных, иначе шаг 2 оказывается избыточным).
При сборе аналитики с помощью ЦУП "Анализ ожиданий на блокировках" с целью экономии времени разработчика в будущем автоматически добавляется показатель "Анализ запросов", подразумевая, что ожидания на блокировках являются только одной из возможных причин колебаний времени выполнения запросов.
Повторим, что в случае использования ЦУП ничего дополнительно делать не потребуется, т.к. разобранный анализ будет уже включать в себя ожидания на блокировках на уровне СУБД.
В случае выбора "Блокировка СУБД" вы сможете увидеть сначала небольшую детализацию о запросах, которые участвовали в ожидании.
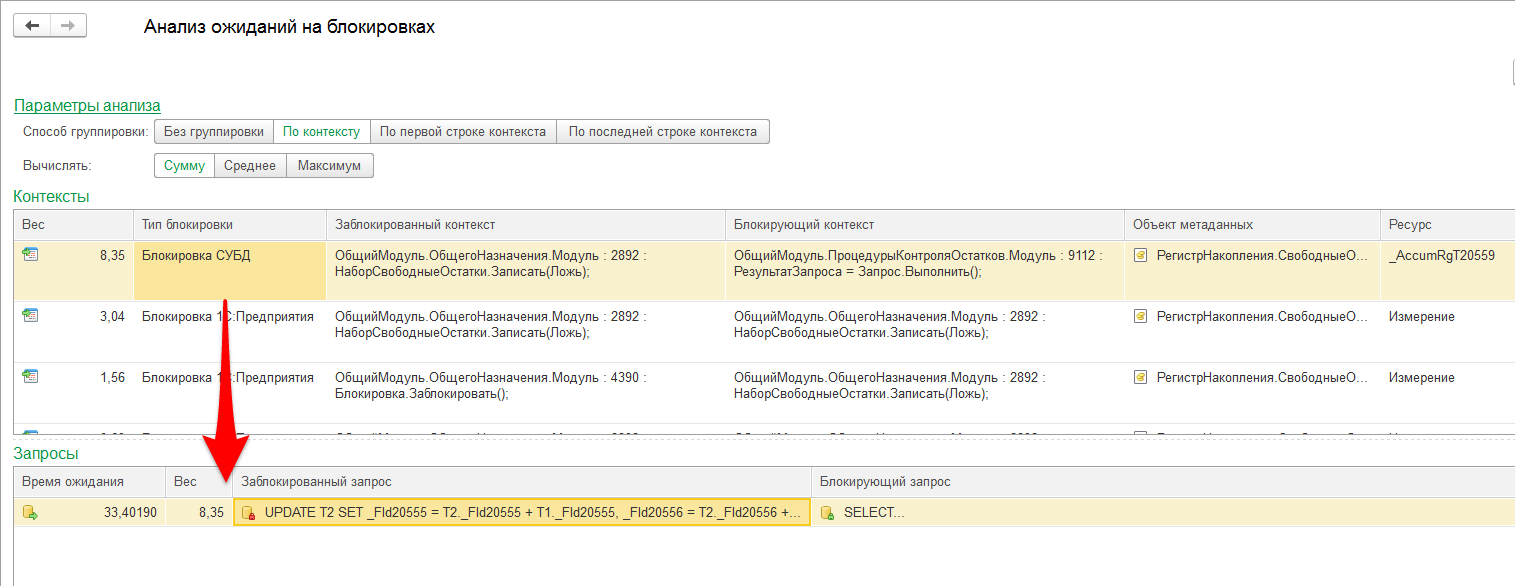
(рис.6. Детализация по блокировке на уровне СУБД в ЦУП)
Однако по двойному щелчку по строке в разделе "Запросы" по заблокированному или блокирующему контексту, вы увидите детализацию по этим запросам,
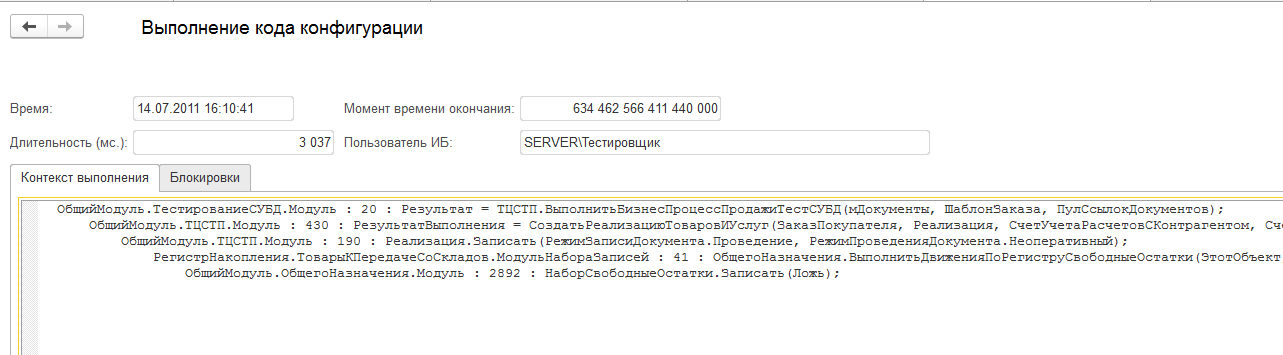
(рис.7. Стек запроса из аналитики ожидания установки блокировки в ЦУП)
а также по блокировкам.
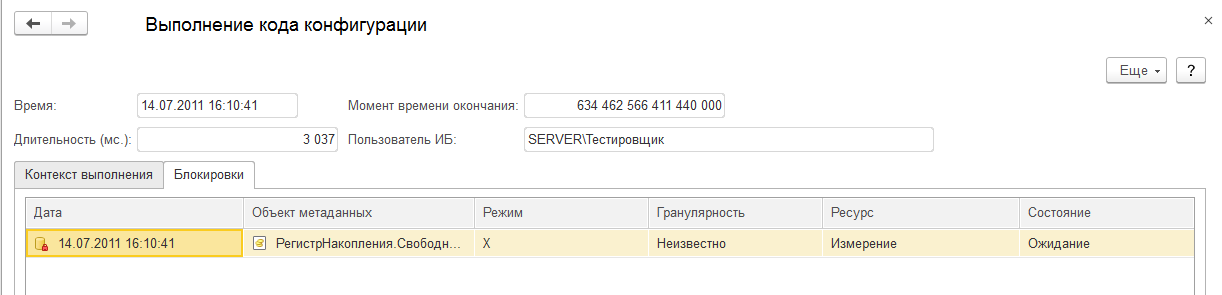
(рис.8. Детализация по блокировке на уровне СУБД в ЦУП)
Для того, чтобы собрать аналогичную информацию вручную, для MS SQL Server потребуется воспользоваться различными инструментами.
В системе (если не запрещено требованиями назначения функциональности) постоянно работает "Сервис вспомогательных функций кластера", который обеспечивает периодическое выполнение запроса (например, для MS SQL Server) в rphost-ах кластера вида
SELECT spid, blocked FROM master.dbo.sysprocesses WITH(NOLOCK) WHERE blocked > 0 AND lastwaittype LIKE 'LCK_%'
для получения информации о блокировках, и фиксирует их в событиях в технологическом журнале.
Свойства таких событий:
? lka=‘1’ – поток является источником блокировки.
? lkp=‘1’ – поток является жертвой блокировки.
? lkpid – номер запроса к СУБД, "кто кого заблокировал" (только для потока-жертвы блокировки). Например, ‘423’.
? lkaid – список номеров запросов к СУБД, "кто кого заблокировал" (только для потока-источника блокировки). Например, ‘271,273,274’.
? lksrc – номер соединения источника блокировки, если поток является жертвой, например, ‘23’.
? lkpto – время в секундах, прошедшее с момента обнаружения, что поток является жертвой. Например: ‘15’.
? lkato – время в секундах, прошедшее с момента обнаружения, что поток является источником блокировок. Например, ‘21’.
Записи таких событий в технологическом журнале могут помочь в понимании общей картины проблемы, но не являются единственным средством для расследования ожиданий на транзакционных блокировках.
В случае наличия воспроизведения проблемы в MS SQL Server можно воспользоваться отчетом по динамическим представлениям "Top Transactions by Locks Count", который позволит увидеть транзакции, которые удерживали наибольшее число блокировок.
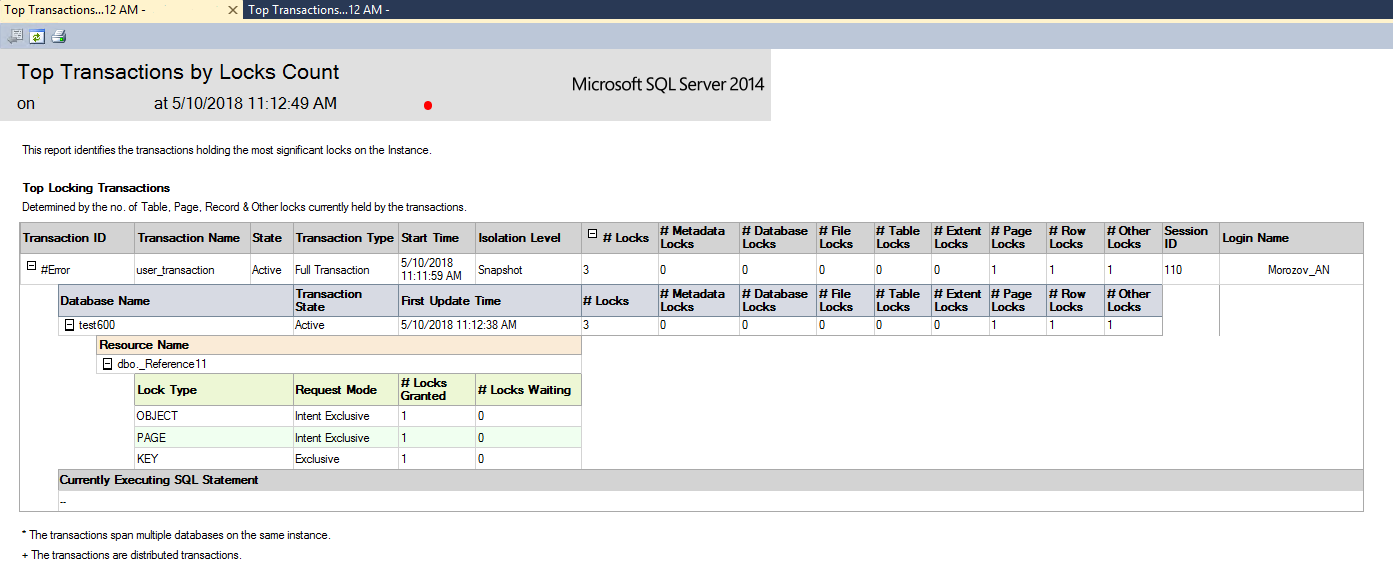
(рис.9. Стандартный отчет по транзакция с блокировками в MS SQL Server Management Studio)
Однако получить соответствие таблиц в базе данных именам таблиц информационной базы придется отдельно, воспользовавшись методов встроенного языка 1С:Предприятия 8 ПолучитьСтруктуруХраненияБазыДанных().
Для того, чтобы получить соответствие запросов, установивших транзакционные блокировки на СУБД, контекстам встроенного языка, потребуется собрать технологический журнал. Для случая работы с MS SQL Server или PostgreSQL он будет выглядеть так:
Копировать в буфер обмена
<?xml version="1.0" encoding="UTF-8"?> <config xmlns="http://v8.1c.ru/v8/tech-log"> <log location="G:\LOGS\DB" history="2"> <event> <eq property="Name" value="DBMSSQL" /> </event> <event> <eq property="Name" value="DBPOSTGRS" /> </event> <event> <eq property="Name" value="SDBL" /> <eq property="Func" value="BeginTransaction" /> </event> <event> <eq property="Name" value="SDBL" /> <eq property="Func" value="RollbackTransaction" /> </event> <event> <eq property="Name" value="SDBL" /> <eq property="Func" value="CommitTransaction" /> </event> <property name="all" /> </log> <plansql/> </config>
Запросы будут содержать искомые контексты на встроенном языке 1С:Предприятия 8. Стоит обратить внимание, что в этом примере настройки добавлен сбор планов запросов <plansql/>, который внесет дополнительные накладные расходы на сбор данных, однако позволит в случае нахождения подозреваемых запросов сразу посмотреть на план запросов и сделать выводы о проблемах. Без настройки <plansql/> сбор планов запросов по умолчанию не происходит.
Для получения более подробной информации о том, что происходит на уровне СУБД MS SQL Server можно воспользоваться MS SQL Profiler или механизмом расширенных событий.
В случае относительно небольшой нагрузки на рабочей системе (не более нескольких сотен пользователей, одновременно работающих в системе в обычном темпе) возможно собрать дополнительную информацию с помощью MS SQL Profiler.
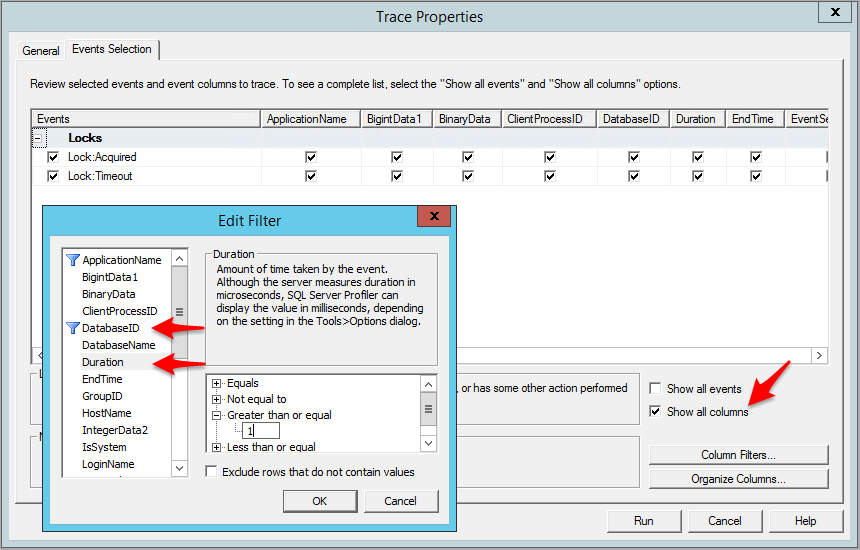
(рис.10. Настройка трассировки в MS SQL Server Profiler)
Включать сбор такой трассировки лучше не из интерфейса, а преварительно сохранив трассировку в виде скрипта для запуска сбора трассировки на сервере. Это необходимо сделать для уменьшения возможного падения производительности в процессе сбора собираемых данных в рабочей системе.
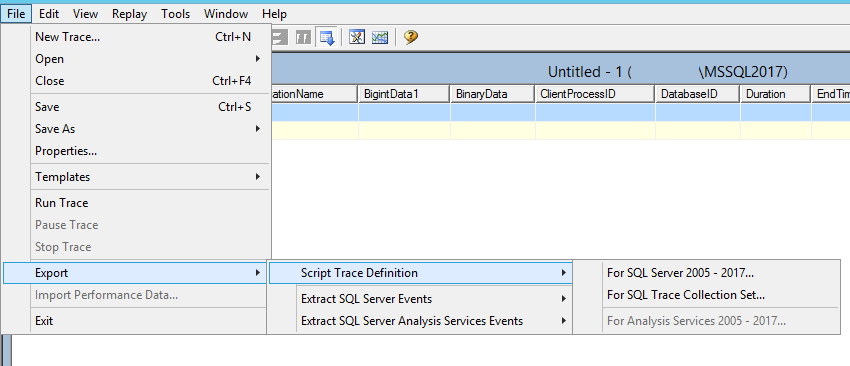
(рис.11. Сохранение трассировки MS SQL Server Profiler в виде скрипта для запуска сбора трассировки на сервере)
В полученном скрипте стоит обратить внимание на возможность регулировки объема собранной трассировки, а также на комментарий, обязывающий изменить путь сбора данных.
set @maxfilesize = 5 -- Please replace the text InsertFileNameHere, with an appropriate -- filename prefixed by a path, e.g., c:\MyFolder\MyTrace. The .trc extension -- will be appended to the filename automatically. If you are writing from -- remote server to local drive, please use UNC path and make sure server has -- write access to your network share exec @rc = sp_trace_create @TraceID output, 0, N'InsertFileNameHere', @maxfilesize, NULL if (@rc != 0) goto error
При сборе данных с помощью трассировки MS SQL Profiler стоит помнить, что:
В случае значительной нагрузки (тысячи пользователей, одновременно работающих в одной информационной базе) имеет смысл вместо MS SQL Profiler воспользоваться механизмом расширенных событий.
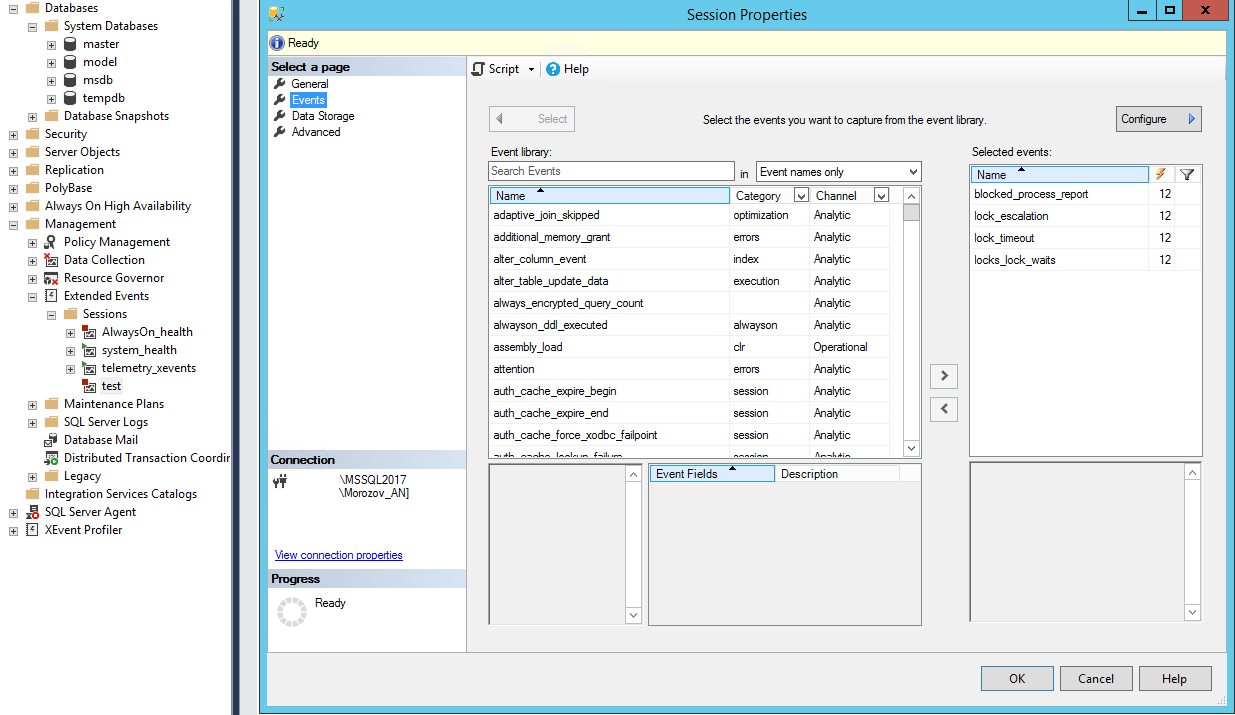
(рис.12. Настройка сбора расширенных событий в MS SQL Server Management Studio)
Обратите внимание на событие blocked_process_report.
Для его настройки потребуется также установить в свойствах экземпляра сервера в разделе Advanced параметр "Blocked Process Threshold" в число секунд, по превышению которых будет сформировано событие. Для MS SQL Server также можно воспользоваться следующим способом:
Копировать в буфер обмена
sp_configure 'show advanced options', 1 ; GO RECONFIGURE ; GO sp_configure 'blocked process threshold', 10 ; GO RECONFIGURE ; GO
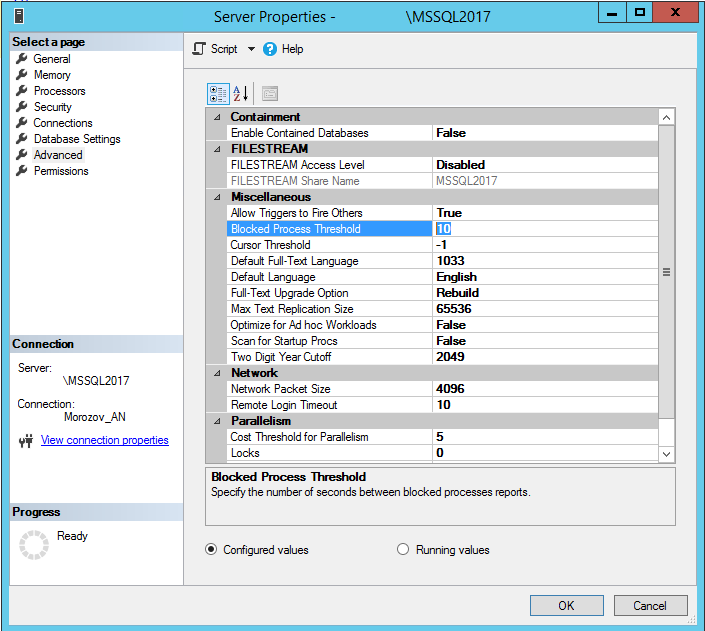
(рис.13. Изменение общих свойств экземпляра сервера в MS SQL Server Management Studio)
Собранную трассировку вы сможете загрузить в таблицу, это стоит делать, т.к. анализ путем "просмотра глазами" кажется достаточно неудобным.
Для этого необходимо создать таблицу, затем можно воспользоваться sys.fn_xe_file_target_read_file для загрузки трассировки в эту таблицу, например:
-- создадим таблицу
Копировать в буфер обменаCREATE TABLE [dbo].[trace]( [TextData] [ntext] NULL, [DatabaseID] [int] NULL, [TransactionID] [int] NULL, [SPID] [int] NULL, [Duration] [bigint] NULL, [StartTime] [datetime] NULL, [EndTime] [datetime] NULL, [Reads] [bigint] NULL, [Writes] [bigint] NULL, [CPU] [int] NULL, [HashSQL] [varchar](4000) NULL, [HashSQLMD5] [varbinary](32) NULL ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY];
-- загрузка данных трассировки в таблицу для ms sql 2012+
Копировать в буфер обменаINSERT INTO [dbo].[trace](TextData, DatabaseID, TransactionID, SPID, Duration, StartTime, EndTime, Reads, Writes, CPU, HashSQL, HashSQLMD5) SELECT TextData AS TextData, DatabaseID AS DatabaseID, TransactionID as TransactionID, SPID AS SPID, Duration AS Duration, DATEADD(millisecond, -Duration, EndTime) AS StartTime, EndTime AS EndTime, Reads AS Reads, Writes AS Writes, CPU AS CPU, NULL AS HashSQL, NULL AS HashSQLMD5 FROM ( SELECT event_data.value('(event/action[@name="sql_text"])[1]', 'nvarchar(max)') AS TextData, event_data.value('(event/action[@name="database_id"])[1]', 'int') AS DatabaseID, event_data.value('(event/action[@name="transaction_id"])[1]', 'int') AS TransactionID, event_data.value('(event/action[@name="session_id"])[1]', 'int') AS SPID, event_data.value('(event/data[@name="duration"])[1]', 'bigint') AS Duration, event_data.value('(event/@timestamp)[1]', 'datetime') AS EndTime, event_data.value('(event/data[@name="physical_reads"]/value)[1]', 'bigint') AS Reads, event_data.value('(event/data[@name="writes"])[1]', 'bigint') AS Writes, event_data.value('(event/data[@name="cpu_time"])[1]', 'bigint') AS CPU FROM ( SELECT CAST(event_data AS XML) AS event_data FROM sys.fn_xe_file_target_read_file('E:\MSSQL\Trace\queries*.xel', null, null, null) ) xel ) AS rawData WHERE TextData IS NOT NULL;
Необходимо обратить внимание, что список полей в примере выше может меняться в зависимости от настройки сбора расширенных событий. При выполнении настроек нужно внимательно проверить состав полей, создаваемых в таблице и загружаемых в нее. Это можно сделать, сохранив настроенную трассировку в виде скрипта. В противном случае вы можете не увидеть все данные, которые вы собирали.
При детальном рассмотрении ожиданий на блокировках на уровне СУБД необходимо помнить, что механизмы СУБД могут устанавливать блокировки не на то, на что вы на самом деле думаете или ожидаете. Реализованная логика может быть куда сложнее того, что покажется на первый взгляд. Но всё же иногда может потребоваться заглянуть чуть глубже, чтобы немного больше понять суть происходящего. Например, пересечение двух транзакций может также возникнуть в результате особенностей реализации механизмов в конкретной СУБД. Допустим, мы видим, что две транзакции пересеклись на определенной странице, хотя данные различны, а планы запросов не подразумевают пересечений. Но обычно такого не происходит. Как же увидеть детали, когда мы видим пересечение двух транзакций с различными данными?

(рис.14. Пример ресурса в пересечении двух транзакций в MS SQL Server)
Например, видим, что Resourse (для Type = PAGE) 1:1026.
В этом случае увидеть детали поможет включение trace флага 3604:
DBCC TRACEON(3604, -1);
После включения trace флага появляется возможность (например, по базе 'test') получить детали, например, так:
DBCC PAGE('test', 1, 1026, 3);
В полученном выводе можно увидеть данные страницы, где было пересечение. Необходимо не забыть выключить trace флаг после получения необходимых для расследования данных:
DBCC TRACEOFF(3604, -1);
В случае необходимости расследования ожиданий на СУБД PostgreSQL необходимо знать, что разработчики 1С:Предприятия 8 считают, что ожиданий на СУБД PostgreSQL при использовании управляемого режима управления блокировками данных возникать не должно, ожидания должны возникать только на управляемых блокировках. Все сценарии работы с 1С:Предприятием 8 и СУБД PostgreSQL, в которых ожидания не возникли на уровне управляемых блокировок, но воспроизвелись на уровне PostgreSQL, необходимо документировать и отправлять информацию разработчикам в тех поддержку на v8@1c.ru или по адресу CorpTechSupport@1c.ru, если проблема мешает в работе корпоративному клиенту. Однако даже в случае их нахождения это все равно ошибки, которые необходимо устранять, не дожидаясь предложений по решению от фирмы "1С".
Для получения списка текущих установленных блокировок в PostgreSQL можно воспользоваться представлением pg_locks, например:
SELECT
Копировать в буфер обменаl.mode, d.datname, c.relname, l.granted, l.transactionid FROM pg_locks AS l LEFT JOIN pg_database AS d ON l.database= d.oid LEFT JOIN pg_class AS c ON l.relation = c.oid;

(рис.15. Пример наложенных блокировок в PostgreSQL)
Для получения текста запроса можно воспользоваться представлением pg_stat_activity, например:
Копировать в буфер обменаSELECT st.pid, st.query FROM pg_stat_activity as st WHERE st.state = 'active' AND st.backend_xid = 4321;

(рис.16. Пример запроса, полученного из представлений в PostgreSQL)
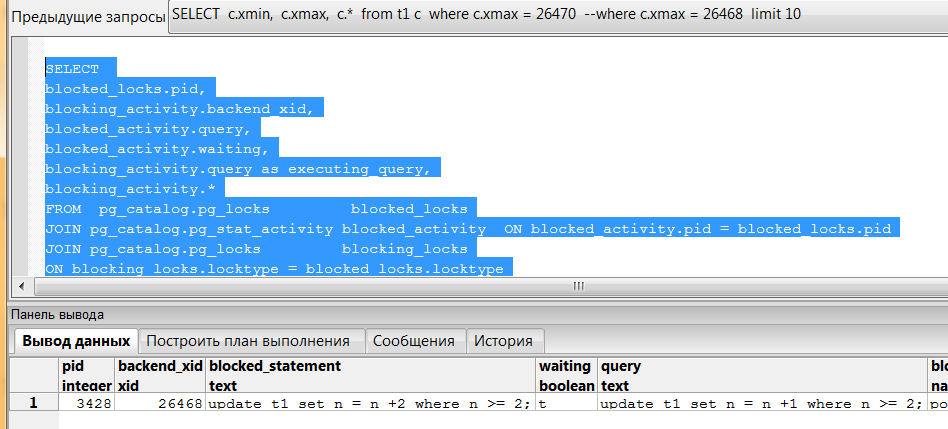
Получить информацию о транзакциях, ожидающих на транзакционных блокировках в PostgreSQL можно, например, следующим запросом:
Копировать в буфер обмена
SELECT
blocked_locks.pid AS blocked_pid,
blocked_activity.usename AS blocked_user,
blocking_locks.pid AS blocking_pid,
blocking_activity.usename AS blocking_user,
blocked_activity.query AS blocked_statement,
blocking_activity.query AS current_statement_in_blocking_process,
blocked_activity.application_name AS blocked_application,
blocking_activity.application_name AS blocking_application
FROM pg_catalog.pg_locks blocked_locks
JOIN pg_catalog.pg_stat_activity blocked_activity
ON blocked_activity.pid = blocked_locks.pid
JOIN pg_catalog.pg_locks blocking_locks
ON blocking_locks.locktype = blocked_locks.locktype
AND blocking_locks.DATABASE IS NOT DISTINCT FROM blocked_locks.database
AND blocking_locks.relation IS NOT DISTINCT FROM blocked_locks.relation
AND blocking_locks.page IS NOT DISTINCT FROM blocked_locks.page
AND blocking_locks.tuple IS NOT DISTINCT FROM blocked_locks.tuple
AND blocking_locks.virtualxid IS NOT DISTINCT FROM blocked_locks.virtualxid
AND blocking_locks.transactionid IS NOT DISTINCT FROM blocked_locks.transactionid
AND blocking_locks.classid IS NOT DISTINCT FROM blocked_locks.classid
AND blocking_locks.objid IS NOT DISTINCT FROM blocked_locks.objid
AND blocking_locks.objsubid IS NOT DISTINCT FROM blocked_locks.objsubid
AND blocking_locks.pid != blocked_locks.pid
JOIN pg_catalog.pg_stat_activity blocking_activity
ON blocking_activity.pid = blocking_locks.pid
WHERE
NOT blocked_locks.GRANTED;
Для включения сбора данных об ожиданиях в журнал PostgreSQL необходимо добавить секцию log_lock_waits = on в postgresql.conf. Тогда настройка журналов в postgresql.conf может выглядеть так:
Копировать в буфер обмена
log_filename = 'postgresql-%Y-%m-%d.log' log_rotation_size = '0' log_timezone = 'W-SU' log_truncate_on_rotation = 'on' log_min_duration_statement = 0 log_autovacuum_min_duration = 0 log_line_prefix = '%t [%p]: [%l-1] user=%u,db=%d,app=%a,client=%h ' log_checkpoints = on log_connections = on log_disconnections = on log_lock_waits = on log_temp_files = 0
(рис.17. Пример пересечения двух транзакций в PostgreSQL)
В случае сбора журналов в PostgreSQL иногда удобнее рассматривать журналы не в текстовом представлении, а в виде проанализированного отчета в html. Для этого можно воспользоваться инструментом PgBadger.
Таким образом, можно заметить, что сбор данных по ожиданиям на блокировках на уровне СУБД является реальной задачей, но достаточно трудоемкой без использования ЦУП.
Если вы всё же решились расследовать ожидания на блокировках без использования ЦУП, то общий подход на этом шаге будет такой:
Трассировка MS SQL Profiler, расширенные события для MS SQL Server или журнал PostgreSQL позволят вам найти транзакции, ресурсы, запросы. Но для получения соответствия найденных данных коду в конфигурации 1С:Предприятие 8 потребуется собирать технологический журнал и/или пользоваться методом встроенного языка 1С:Предприятия 8 ПолучитьСтруктуруХраненияБазыДанных(). Например, аналогичный сбор и сопоставление полученных данных MS SQL Server выполняет ЦУП.
Таким образом, способы устранения проблем сводятся к двум основным возможностям:
Собрав необходимые данные, разработчик должен ответить на вопросы:
Нужно понимать, что нельзя просто убрать транзакционную блокировку, т.к. она нужна для обеспечения целостности. Пути решения могут быть следующие, если точно известно, что пересечение транзакций произошло на разных данных с точки зрения пользователей (и не требуется корректировка бизнес-процесса):
Подробнее о блокировках данных можно прочитать в статье "Блокировки данных в 1С:Предприятии 8" (https://kb.1c.ru/articleView.jsp?id=30).
Подробнее о типичных причинах избыточных блокировок можно прочитать в статье "Типичные причины избыточных блокировок и методы оптимизации" (https://kb.1c.ru/articleView.jsp?id=45).