Технологические вопросы крупных внедрений
13.05.2016
Методика расследования проблем производительности в сервисе 1cfresh
В статье рассказывается о методике расследования причин проблем производительности в облачных сервисах, построенных на основе технологии 1cfresh.
Облачные сервисы, построенные на основе технологии 1cfresh, обладают рядом особенностей по сравнению с обычными внедрениями. В том числе:
- Абсолютное большинство пользователей работает территориально удаленно от администраторов сервиса, зачастую в другом часовом поясе;
- Удаленный доступ к рабочему месту пользователей существенно затруднен или невозможен;
- Предъявляются повышенные требования к производительности и доступности информационных баз;
- Нельзя воспользоваться отладкой на рабочих серверах;
- На рабочей площадке ограничена возможность использования типовых инструментов расследования проблем, типа ЦУПа, из-за их негативного влияния на производительность сервиса;
- Сервис развернут на большом количестве серверов, в результате сложность поиска проблемы возрастает в разы;
- Накладываются строгие ограничения на доступ к данным информационной базы, в результате данные для воспроизведения очень сложно получить.
Эти особенности необходимо учитывать при расследовании проблем производительности в процессе эксплуатации информационных систем, построенных на основе технологии 1cfresh.
Проблемы производительности
Категории проблем
На первом шаге анализа необходимо понять, с проблемой какого рода вы встретились:
- Общая медленная работа сервиса у всех пользователей;
- Общая медленная работа сервиса у определенных пользователей;
- Медленная работа определенной функциональности у всех пользователей, либо у значительной части пользователей;
- Медленная работа определенной функциональности у определенных пользователей.
Такую классификацию необходимо выполнить, т.к. причины проблем разного вида существенно различаются, так же как и методики их расследования.
Методы классификации
В процессе анализа необходимо учитывать совокупность показателей, среди которых:
- Время выполнения операций, рассчитаное по различным методикам, например, Apdex или среднее время наихудших замеров;
- Наличие жалоб от других пользователей;
- Счетчики производительности (загруженности) оборудования;
- Счетчики, встроенные в подсистему ЦентрМониторинга;
- Воспроизводится ли проблема в тестовой базе (или в другой ноде) или в тестовой области в рабочей базе.
Для расследования проблем производительности в сервисе критически важно организовать централизованный сбор данных замеров производительности и агрегацию показателей Apdex. Для этого следует использовать возможности ЦКК по импорту замеров производительности. Необходимость использования ЦКК для этой цели связана, во-первых, с возможностью горизонтального масштабирования сервиса, что приводит к тому, что один и тот же пользователь сервиса может работать параллельно в нескольких информационных базах. Как следствие, данные о замерах также хранятся во множестве информационных баз. Во-вторых, доступ с данным замеров в разделенной информационной базе требует наличия у специалиста, занимающегося вопросами производительности, административного доступа к данным, который в общем случае отсутствует. В третьих, в ЦКК встроены намного более развитые средства для анализа замеров, чем в любые другие конфигурации.
Рассмотрим особенности каждого класса проблем подробно.
Общая медленная работа сервиса у всех пользователей
Характерным признаком этого класса является то, что пользователь не может указать на конкретную операцию, которая замедлилась, либо пользователь будет указывать на те операции, которые он выполняет чаще всего.
Для выявления факта того, что проблема воспроизводится у большого количества пользователей (массовая проблема), необходимо понять:
- Есть ли аналогичные обращения от других пользователей
Как правило, массовые проблемы с производительностью сервиса приводят к большому количеству обращений, поэтому перед началом анализа имеет смысл выяснить, единичное ли поступившее обращение или нет.
- Как изменялся Apdex за последнее время
Для этого необходимо проанализировать динамику Apdex и по системе в целом, и по обратившемуся пользователю.
Рекомендуется использовать для этой цели отчет "Анализ производительности" ЦКК, сформировав его с отбором по отдельному пользователю, а затем без отбора.
Например, факт резкого изменения производительности всего сервиса указывает на то, что в системе произошли какие-то изменения:
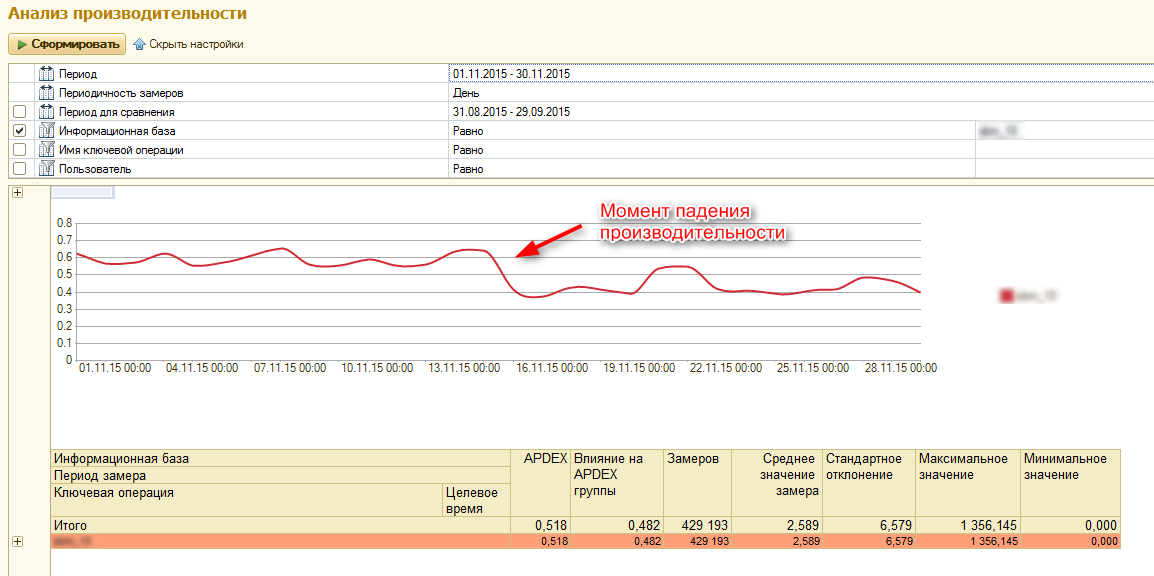
рис.1 График Apdex за период по сервису в целом
Аналогичный график по конкретному пользователю с высокой долей вероятности указывает на то, что проблема этого пользователя заключается именно в проблемах сервиса в целом:
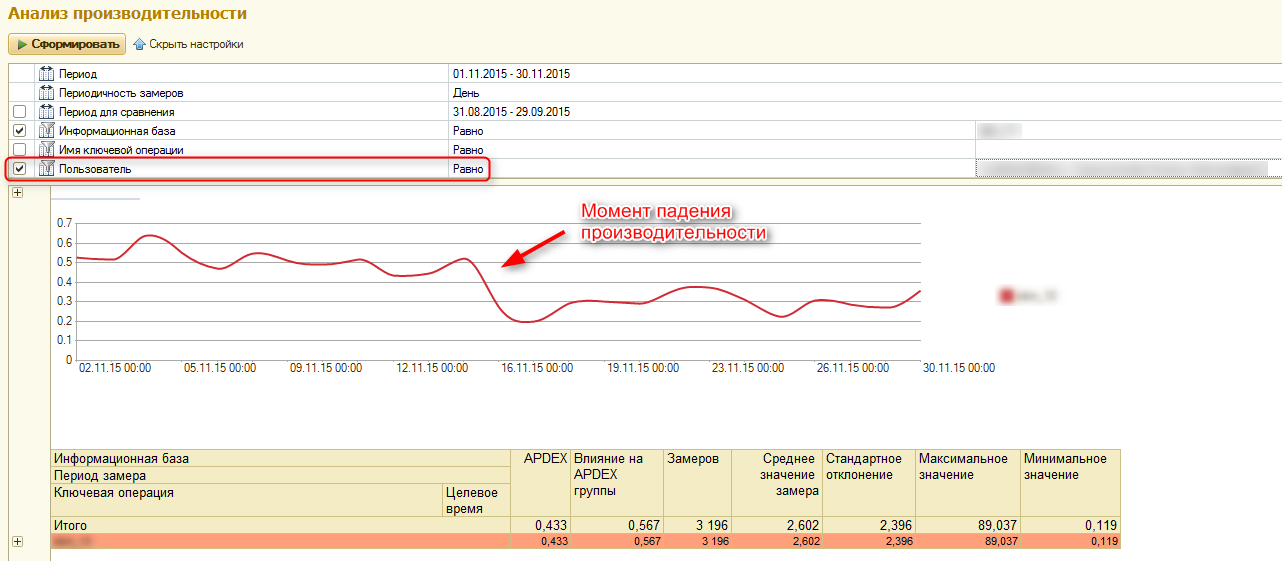
рис.2 График Apdex за период по определенному пользователю
Помимо резкого изменения скорости работы сервиса может наблюдаться и постепенная деградация производительности. Для выявления таких проблем целесообразно анализировать более длительный период времени.
- Дополнительно имеет смысл мониторить среднее время выполнения определенного класса быстрых операций (т.е. выполняющихся в клиентском приложении без использования механизма длительных операций). В качестве такого класса операций может выступать, в частности, время проведения всех видов документов.
Необходимость такого анализа связана с тем, что в некоторых случаях данные Apdex могут не показывать проблему. Например, если в системе постоянно выполняется большое количество ключевых операций с заведомо большим целевым временем, то в этом случае будет регистрироваться большое количество замеров с высоким значением Apdex. В результате проблема может быть замаскирована среди таких операций.
Для выполнения анализа среднего времени выполнения операций можно воспользоваться формой мониторинга ЦКК:
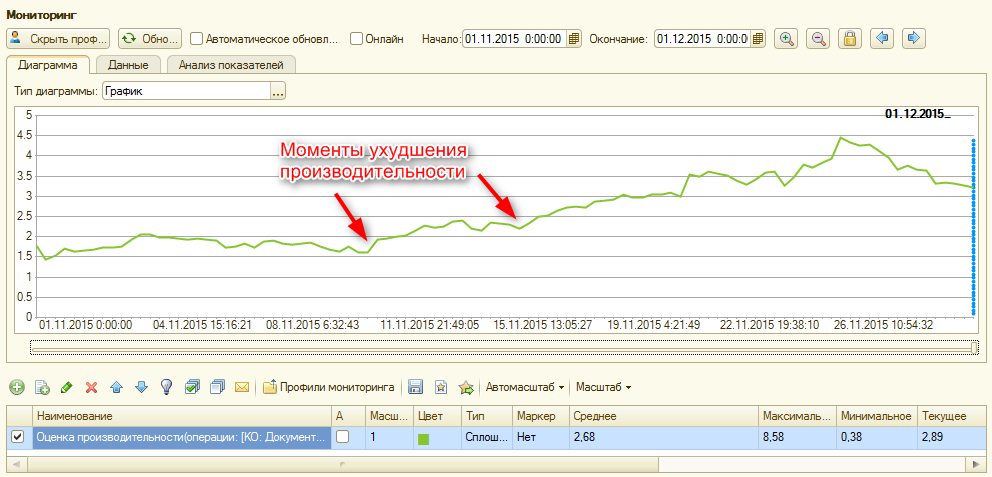
рис.3 График среднего времени выполнения операций за период
Общая медленная работа сервиса у определенных пользователей
Симптомы проблем такого рода, на которые указывают пользователи, обычно полностью совпадают с симптомами предыдущей категории. Однако, в отличие от нее, данные Apdex по пользователю заметно отличаются от показателей сервиса в худшую сторону. Также для этого вида проблем не удается выявить факты деградации общей производительности сервиса, кореллирующие с моментом возникновения проблем у пользователя.
Медленная работа определенной функциональности у всех пользователей, либо у значительной части пользователей
Для этой категории проблем характерно указание конкретных сценариев при описании проблемы пользователем. Этот класс проблем диагностируется так же, как проблемы с общим замедлением сервиса, с тем лишь отличием, что при формировании отчетов требуется дополнительно установить отбор по конкретной ключевой операции.
Медленная работа определенной функциональности у определенных пользователей
В случае если пользователь указывает на конкретный сценарий в котором воспроизводится проблема, и по результатам анализа установлено, что проблема не является массовой, то проблему следует отнести к этой категории.
В этом случае требуется провести проверки и попытаться максимально точно воспроизвести медленную работу определенной функциональности. Если проблема действительно в конкретной реализации функциональности, то проблема должна воспроизвестись.
Типичные причины проблем производительности
Общая медленная работа сервиса у всех пользователей
Возможные причины:
- Резкая деградация производительности
- Изменения в настройке оборудования;
- Изменения в конфигурации информационной базы;
- Изменения настроек программных продуктов;
- Плавная деградация производительности
- Постепенно нарастающий дефицит вычислительных мощностей;
- Постепенно нарастающий дефицит пропускной способности дискового хранилища;
- Постепенно нарастающий дефицит пропускной способности сети;
- Деградация производительности неоптимальных запросов вследствие роста объема базы;
- Деградация производительности вследствие постепенного накопления изменений конфигурации информационной базы, негативно влияющих на производительность.
Если в результате анализа выявлено резкое падение производительности, то важно установить точный момент, когда произошла деградация. Опираясь на эту информацию, необходимо проанализировать изменения, произошедшие в системе. Например, среди таких изменений может быть обновление конфигурации информационной базы, включение нового регламентного задания, перемещение виртуального сервера на другое оборудование и т.д.
Если же деградация происходила постепенно, то необходимо понять, с чем связаны наблюдающиеся проблемы.
Для установления факта нехватки производительности оборудования следует организовать сбор сведений о загрузке оборудования. Для этих целей можно использовать как системные средства мониторинга (например, perfmon + logman при использовании ОС Windows), так и возможности ЦКК по сбору сведений о производительности оборудования.
Подробнее о настройке мониторинга на рабочих серверах можно прочитать тут.
Диагностировать длительные запросы можно путем анализа технологических журналов по событиям DBMSSQL (или другие в зависимости от используемой СУБД) и SDBL, либо используя ЦУП. При использовании MSSQL также имеет смысл проанализировать, какие виды ожиданий чаще всего возникают на сервере (подробнее тут).
Диагностировать длительные вызовы можно путем анализа технологических журналов по событиям CALL, SCALL, VRSREQUEST, VRSRESPONSE.
Также проблемы производительности могут постепенно накапливаться по мере перехода на новые версии конфигураций. Проверить факт такого изменения можно, если провести нагрузочное тестирование, и сравнить производительность двух версий - актуальной, и старой версии, во время работы на которой проблем производительности не наблюдалось. При этом важно проведение нагрузочных тестов в максимально стабильных условиях. Для определения возможности сравнения достаточно провести несколько тестов подряд и оценить разброс показателей производительности на текущем оборудовании и текущей конфигурации системы. Увеличение разброса свидетельствует об очередях на различных уровнях работы информационной системы.
Общая медленная работа сервиса у определенных пользователей
Есть две основных причины проблем такого рода:
- Нетипичное наполнение области
- Большой объем данных
- Нестандартные настройки
- Проблемы подключения
- Медленный компьютер
- Низкая скорость интернет-канала
- Нестабильный интернет-канал
Для расследования таких проблем необходимо убедиться, что проблема не связана с конкретными сценариями работы. Зачастую, под общей медленной работой сервиса пользователи на самом деле имеют в виду медленную работу тех операций, которые они выполняют чаще всего. Поэтому необходимо подробно распросить пользователя о тех сценариях, на которых воспроизводится проблема, и проверить воспроизведение на копии области.
Если пользователь затрудняется сказать, какие операции работают медленно, то нужно проверить те операции, которые пользователь чаще всего выполняет по данным отчета "Анализ производительности" ЦКК.
Если проблему удалось воспроизвести, то для дальнейшего расследования следует воспользоваться этой методикой.
Если проблему воспроизвести не удалось, то, вероятно, проблема связана с особенностями подключения к сервису конкретного пользователя. Для диагностики проблем такого рода можно воспользоваться обработкой "Диагностика качества подключения", встроенной в менеджер сервиса.
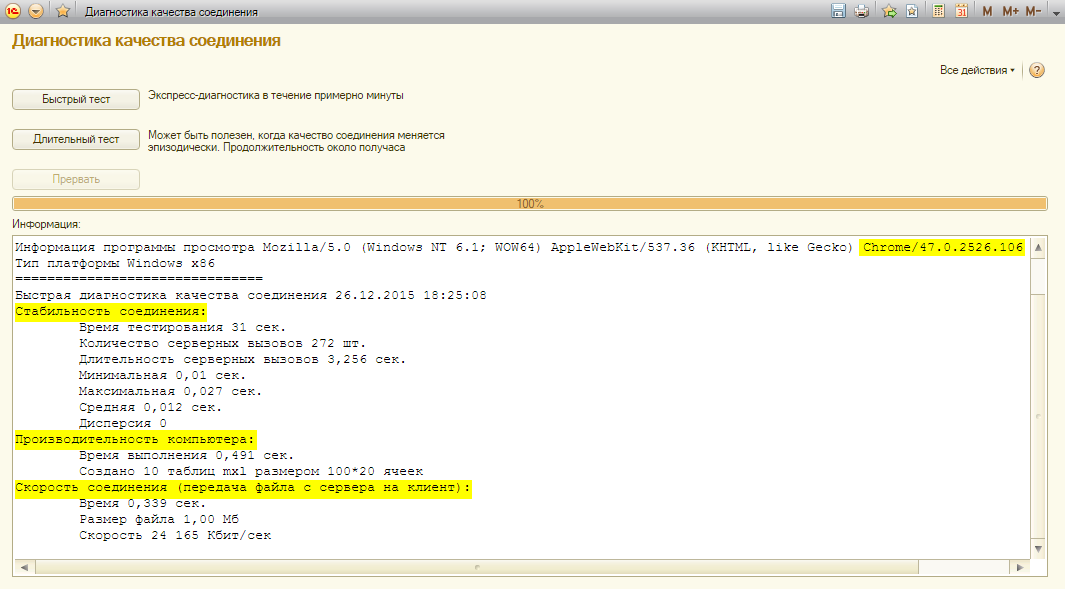
Рис.4 Обработка "Диагностика качества соединения"
Для обеспечения высокого качества работы сервиса необходимо, чтобы:
- Соединение обладало высокой стабильностью (до версии технологической платформы 8.3.6 включительно факт неполучения ответа от сервера приводит к зависанию тонкого клиента)
- Соединение имело хорошую скорость (рекомендуется не менее 2 Мбит)
- Компьютер обладал достаточной производительностью. Конкретное значение определяется эмпирически, и зависит от типа браузера, использованного для выполнения теста; значение на скриншоте - 0.491 - означает хорошую производительность компьютера, в случае если оно получено при использовании Google Chrome. Значения более 1-1.5 сек (в случае использования Google Chrome) обычно указывают на недостаточную производительность клиентского компьютера.
Если пользователь использует медленный компьютер, то для решения проблем производительности рекомендуется использовать тонкий клиент. Если для пользователя принципиально использование браузера, то для достижения наилучшей производительности рекомендуется использование Google Chrome.
Медленная работа определенной функциональности у всех пользователей, либо у значительной части пользователей
В случае если проблема воспроизводится у всех пользователей в определенной функциональности, то для расследования необходимо попробовать воспроизвести проблему на тестовой области данных. Если проблему на имеющихся данных воспроизвести не удается, то необходимо получить данные области одного из тех пользователей, у которых проблема точно воспроизводится, и проверить воспроизведение на этих данных.
Обычно массовые проблемы достаточно легко воспроизводятся, после чего можно приступить к расследованию. Методика расследования описана тут.
Медленная работа определенной функциональности у определенных пользователей
Проблемы такого рода относятся к числу наиболее трудных для расследования. Рекомендуемая последовательность анализа следующая:
- Получить максимально подробное описание проблемы от пользователя;
- Попробовать воспроизвести проблему на копии области пользователя. Если воспроизвести удалось, то выполнить анализ с помощью этой методики.
- Если воспроизвести не удалось, то настроить технологический журнал с событиями DBMSSQL (или другие в зависимости от используемой СУБД), CALL и SCALL.
- Попросить пользователя воспроизвести операцию, и засечь время начала выполнения и длительность операции по секундомеру.
Также это можно выполнить самостоятельно на компьютере пользователя, если проблема воспроизводится "прямо сейчас", и пользователь согласен на удаленное подключение к его компьютеру.
- Если операция относится к числу ключевых, то уточнить точное время начала и окончания операции по данным замеров производительности
- Выяснить номер сеанса по данным журнала регистрации
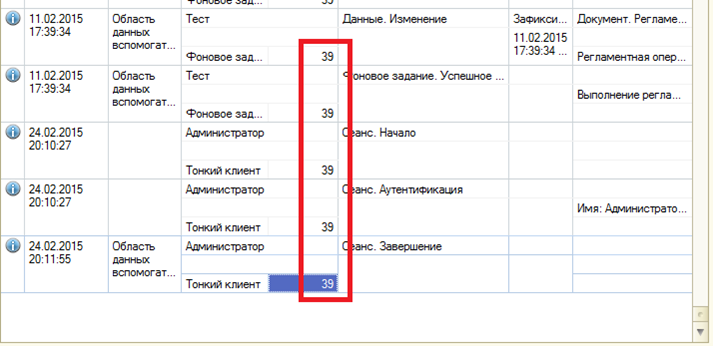
Рис.5 Уточнение номера сеанса по журналу регистрации
- Отфильтровать собранный технологический журнал по номеру сеанса и типу события, используя следующую команду:
cat <ПутьКЖурналам>/*/* | perl -n -e 'if (/^\d\d:\d\d\.\d+/) {$event =~ s/\n/<line>/g; print $event."\n"; $event = "";} $event .= $_; END{print $event."\n"};' | grep "SessionID=<НомерСеанса>" | grep ",<ТипСобытия>," | sed 's/<line>/\n/g' > <ТипСобытия>.txt
где:
- <ПутьКЖурналам> - путь к каталогу с собранными технологическими журналами
- <НомерСеанса> - номер сеанса, в котором выполнялась анализируемая операция
- <ТипСобытия> - тип события (CALL, DBMSSQL или SDBL)
Предварительно на компьютере, на котором выполняется анализ, должен быть установлен cygwin и perl. Скрипт должен выполняться из-под командной оболочки cygwin. Отфильтрованный журнал будет сохранен в файл <ТипСобытия>.txt.
- Посчитать суммарную длительность серверных вызовов (события CALL) и суммарное время выполнения запросов (DBMSSQL, SDBL), используя следующую команду:
cat <ТипСобытия.txt> | awk -F'-' '{mas[$2] += $1; count[$2] += 1;} END {for (i in mas) {print mas[i] " " count[i] " " i};}' | sort -rn > <ТипСобытия_Итого>.txt
где <ТипСобытия> - тип события (CALL, DBMSSQL или SDBL)
- На основе собранной информации попытаться понять, в чем заключается проблема.
Например, если очевидно, что проблема связана с длительным временем выполнения запросов, то проанализировать тексты и, при необходимости планы выполнявшихся запросов (возможно, потребуется собрать дополнительно).