Технологические вопросы крупных внедрений
27.06.2018
Платформа "1С:Предприятие" в своей работе постоянно использует механизм, называемый "сеансовые данные". В этих данных хранится служебная информация, необходимая для работы сеанса "1С:Предприятия". Например, все, что введено в поля ввода на форме, при серверных вызовах сбрасывается в сеансовые данные.
При вызове методов: ПоместитьВоВременноеХранилище, ПоместитьФайл, НачатьПомещениеФайла, значения указанные в параметрах, записываются в сеансовые данные.
При фоновом исполнении отчетов СКД, результат отчета помещается в сеансовые данные, а затем передается в клиентскую часть.
С точки зрения операционной системы, сеансовые данные представляют собой файлы в каталоге …\srvinfo\reg_<номер порта>\snccntx<GUID>.
С точки зрения внутренней структуры - это noSQL база данных (key-value storage).
За работу с сеансовыми данными отвечает менеджер кластера – rmngr.exe Если в кластере несколько рабочих серверов, то сеансовые данные будут расположены в соответствии с требованиями назначения функциональности.
Если требования не заданы, то сеансовые данные распределятся равномерно по всем рабочим серверам.
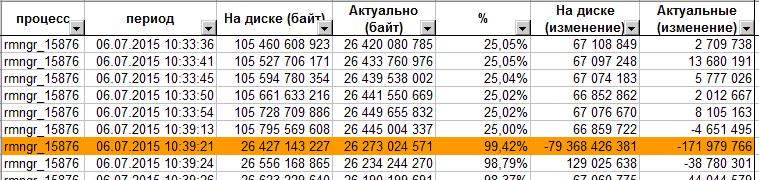
Сеансовые данные растут блоками по 64 Мб. Когда заканчивается блок, то менеджер кластера выделяет следующий блок в 64Мб.Блоки большего объема возможны в результате помещения объемных данных во временные хранилища.
Для обеспечения скорости работы, платформа всегда пишет новые данные в конец, аналогично transaction log в СУБД. Таким образом, размер сеансовых данных постоянно растет. Во всем объеме сеансовых данных, существуют как актуальные, так и устаревшие данные. Актуальность данных определяется способом их помещения:
Перед выделением следующего блока на диске, проверяется, прошло ли 5 секунд с момента выделения предыдущего блока. Если 5 секунд прошло, то запускается "сборщик мусора" (key value garbage collector). Сборщик оценивает процент актуальных сеансовых данных в общем объеме. Если актуальные данные занимают менее 25% от общего объема, то все актуальные данные копируются в новые файлы, а затем все старые файлы сеансовых данных удаляются.
Так как каждый сеанс (клиенты, фоновые задания, web-сервисы) в своей работе постоянно пишет информацию в сеансовые данные, то при большом количестве пользователей, скорость дисковой подсистемы, на которой расположены файлы сеансовых данных, играет очень важную роль. При большом количестве пользователей, рекомендуется располагать файлы сеансовых данных на максимально быстрых дисках. Желательно RAM-drive. Отказоустойчивость дисков не важна, т.к. при потере сеансовых данных, никакой важной информации утеряно не будет.
Следует отметить порядок размещения сеансовых данных. Если поместить во временное хранилище двоичные данные или файл, то эти данные пройдут в качестве потока байт через rphost, затем в rmngr, который сбросит этот поток на диск. Если же, в качестве помещаемого значения, будет выступать коллекция (таблица значений, результат запроса, массив…), то сначала вся эта коллекция разместиться в памяти rphost, а только затем преобразуется в поток байт и будет передана в rmngr.
При работе кластера "1С:Предприятия", файлы сеансовых данных отображаются в память (mapping). Подробнее см. статью.
За счет данного механизма, процесс работает с файлом как с оперативной памятью. Файл загружается в память не целиком, а только необходимая часть.
Однако, в операционной системе Windows, отображенные в память файлы, влияют на счетчик Memory\Available Mbytes. При сильном росте сеансовых данных можно увидеть следующую картину:
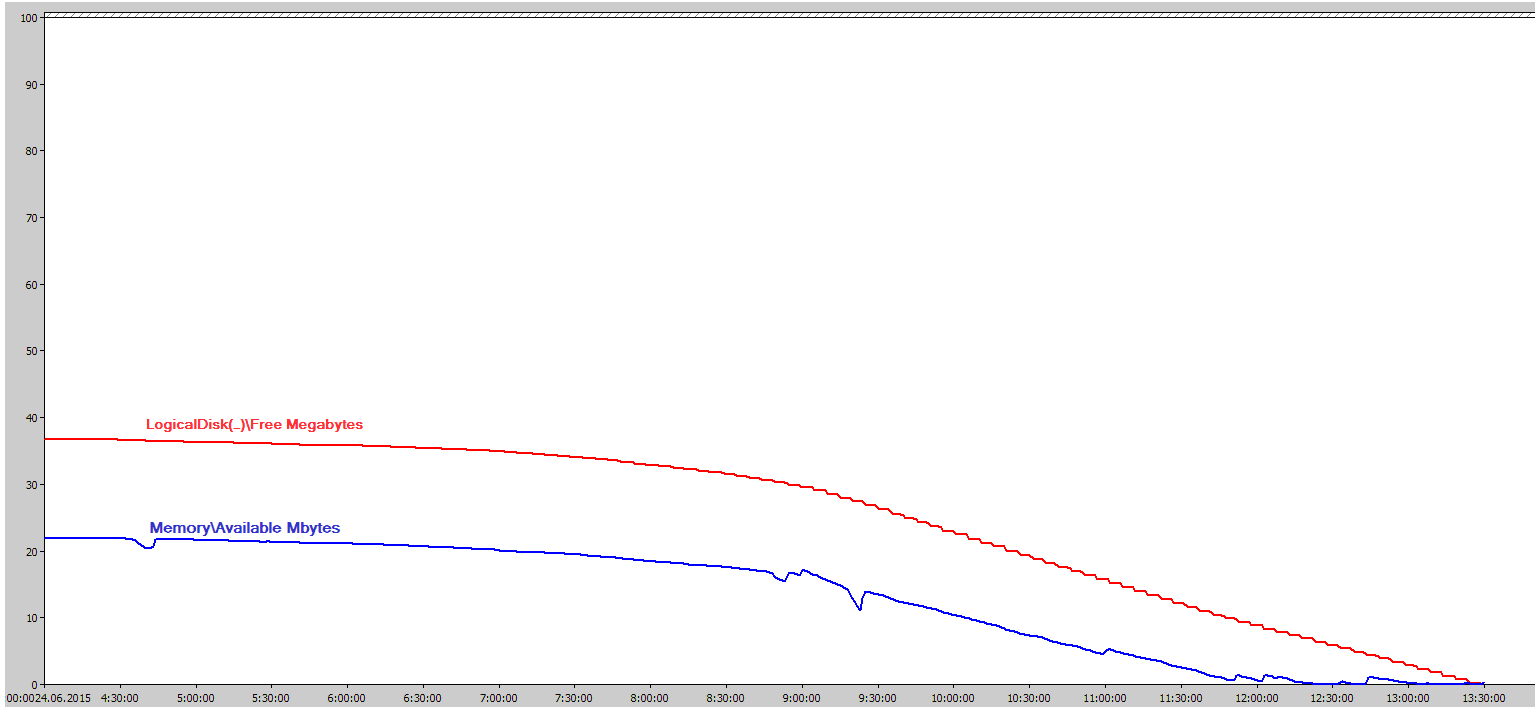
Свободное место на диске, где расположены сеансовые данные, уменьшается синхронно со свободной памятью сервера. На самом деле, если посмотреть данные RamMap то видно, что большая часть оперативной памяти выделена под Mapped File
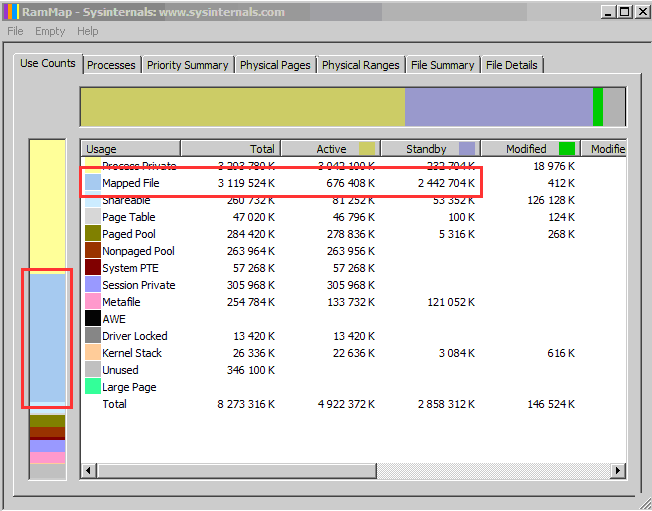
Размер памяти, указанный в колонке Standby – это неиспользуемая память (фактически свободная). При запросе памяти любым процессом, ему будет выделена память из этой области.
Следует учитывать данную особенность счетчика Memory\Available Mbytes при построении систем мониторинга или приложений, которые опираются на объем доступной оперативной памяти.
Для косвенной оценки эффективности работы операционной системы с сеансовыми данными, можно использовать счетчик Memory\Page Faults/sec, который показывает на сколько часто процессы обращаются за страницами в память, но не находят их там и подгружают с диска.
Если значение данного счетчика велико, то это может свидетельствовать о нехватке оперативной памяти для кэширования в ней сеансовых данных. В этом случае, необходимо принять решение об увеличении оперативной памяти, либо об оптимизации работы приложения с сеансовыми данными.

При появлении данной ошибки необходимо действовать по алгоритму:
1. Проверить права на папку сеансовых данных для пользователя, от которого запущена служба сервера "1С:Предприятия". Должны быть полные права.
2. Открыть на рабочем сервере диспетчер задач, установить видимость колонки "Командная строка"
3. Необходимо найти процессы rmngr.exe с одинаковым значением параметра –pid.
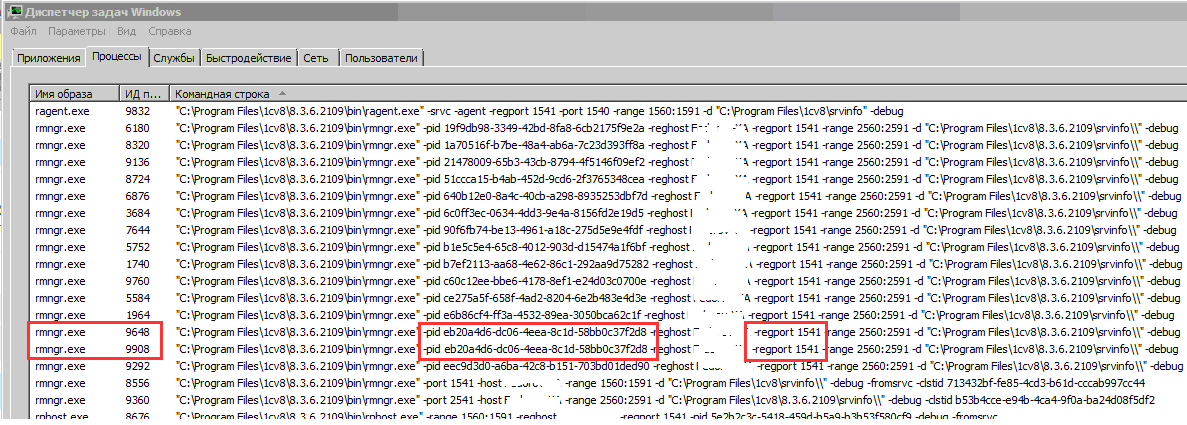
4. Открыть консоль кластера. Развернуть ветку кластера, порт которого соответствует параметру –regport, найденных rmngr.exe с одинаковым значением параметра –pid
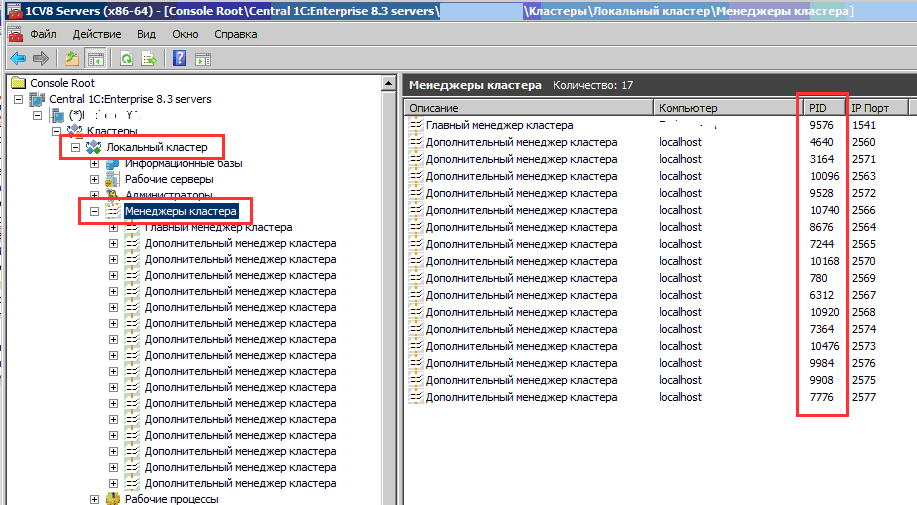
5. Сопоставить PID из диспетчера задач с PID в консоли кластера. Тот процесс rmngr.exe, которого нет в консоли – принудительно завершить.
Необходимо следить за наличием свободного места на диске, где расположены сеансовые данные.
Не следует размещать файлы технологических журналов на одном диске с сеансовыми данными.
Если на диске, где расположены сеансовые данные, закончится место, то картина будет совершенно "апокалиптическая". Менеджер кластера будет постоянно завершаться с формированием дампа. Начнутся сотни попыток запусков рабочих процессов, которые сразу же будут завершаться с ошибками. После того, как на диске появится свободное место, сервер "1С:Предприятия" запустится в нормальном режиме.
Так же, необходимо следить за размером самих сеансовых данных. Если периодически их размер становится существенным, то необходимо обратить на это особое внимание. Следует помнить, что при срабатывании "сборки мусора" необходимо наличие свободного места на диске, в размере 25% от общего объема сеансовых данных. Если этих 25% не будет, то кластер завершит свою работу аварийно.
Изменить расположение сеансовых данных, можно указав параметр –d в строке запуска службы агента сервера.
В данном каталоге, также расположены: реестр кластера, индекс полнотекстового поиска и журнал регистрации.
Чаще всего при выполнении процедуры ПоместитьВоВременноеХранилище, указывается идентификатор формы (ЭтаФорма.УникальныйИдентификатор). Как написано в документации, при указании идентификатора формы данные перестают считаться актуальными после того как форма будет закрыта.
Однако, если форма содержит в себе циклические ссылки (см. статью), то после закрытия формы она не уничтожается. Это приводит следующим отрицательным эффектам:
Чтобы избежать данной ситуации, необходимо исключить все циклические ссылки в форме (см. статью).
Необходимо стараться формировать отчеты СКД в фоновом режиме. Так как результат отчета помещается во временное хранилище фоновым заданием, то после завершения задания данный результат будет считаться неактуальным.
Необходимо собрать технологический журнал:
Для 8.3.5
Копировать в буфер обмена<config xmlns="http://v8.1c.ru/v8/tech-log"> <log history="24" location="c:\log\sntx"> <event> <eq property="name" value="CONN"/> </event> <event> <eq property="name" value="CALL"/> <eq property="Interface" value="90b77326-8e4a-4195-b980-d758277d1f03"/> </event> <event> <eq property="name" value="SCALL"/> <eq property="Interface" value="90b77326-8e4a-4195-b980-d758277d1f03"/> </event> <property name="all"/> </log> </config>Копировать в буфер обмена
Для 8.3.6
Копировать в буфер обмена<config xmlns="http://v8.1c.ru/v8/tech-log"> <log history="24" location="c:\log\sntx"> <event> <eq property="name" value="CONN"/> </event> <event> <eq property="name" value="CALL"/> <eq property="IName" value="ISeanceContextStorage"/> <eq property="MName" value="seanceParametersPresave"/> </event> <event> <eq property="name" value="SCALL"/> <eq property="IName" value="ISeanceContextStorage"/> <eq property="MName" value="seanceParametersPresave"/> </event> <property name="all"/> </log> </config>
Данный технологический журнал может занимать значительный объем. Поэтому необходимо располагать его на дисках имеющих достаточно свободного пространства, периодически переносить старые файлы журнала на другой диск и там архивировать (сохраняя структуру папок).
После того, как технологический журнал будет собран, необходимо провести "парсинг" и выгрузить его данные в файлы csv формата:
На основании данных, которые собраны в папках rmngr_*, необходимо сформировать csv файл вида:
Копировать в буфер обмена<файл ТЖ>;<CallID>;<InBytes>
где:
Пример:
В файле …/rmngr_7188/15063011.log есть строка:
Копировать в буфер обмена00:00.063040-93009,CALL,1,process=rmngr,p:processName=RegMngrCntxt,t:clientID=7518,t:applicationName=ServerProcess,t:computerName=SERVER,
Interface=90b77326-8e4a-4195-b980-d758277d1f03,Method=9,CallID=141192031,Memory=1137,MemoryPeak=9258,InBytes=142428,OutBytes=142428
Данная строка должна быть преобразована в строку:
Копировать в буфер обмена15063011;141192031;142428
Необходимо исключить из итогового файла строки с InBytes=0, т.к. они не представляют интереса, но занимают значительный объем.
На основании данных, которые собраны в папках rphost_*, необходимо сформировать csv файл вида:
Копировать в буфер обмена<процесс>;<файл ТЖ>;<t:clientID>;<CallID>
где:
Пример:
В файле …/rphost_1352/15063011.log есть строка:
Копировать в буфер обмена00:00.064001-108993,SCALL,2,process=rphost,p:processName=DB,t:clientID=518,t:applicationName=1CV8,t:computerName=TSERVER,t:connectID=5880,SessionID=4621,Usr=Пользователь,AppID=1CV8,
ClientID=404,Interface=90b77326-8e4a-4195-b980-d758277d1f03,Method=0,CallID=-1814608052
Данная строка должна быть преобразована в строку:
Копировать в буфер обменаrphost_1352;15063011;518;-1814608052
На основании данных, которые собраны в папках rphost_*, необходимо сформировать csv файл вида:
Копировать в буфер обмена<процесс>;<t:clientID>;<Usr>
где:
Пример:
В файле …/rphost_1352/15063011.log есть строка:
Копировать в буфер обмена06:29.468020-0,CONN,3,process=rphost,p:processName=DB,t:clientID=518,t:applicationName=1CV8,t:computerName= TSERVER,t:connectID=5590,SessionID=3012,Usr= Пользователь,AppID=1CV8,
ClientID=555,Protected=0,Txt='Connected, client=(23)[::1]:53147, server=(23)[::1]:1541'
Данная строка должна быть преобразована в строку:
Копировать в буфер обменаrphost_1352;195;Пользователь
В итоге должно получиться 3 файла: scall.csv, call.csv, conn.csv
Пример создания файлов csv, на основании данных технологического журнала, см. в обработке.
Необходимо создать пустую базу данных (MS SQL Server), в которую добавить таблицы:
Копировать в буфер обменаCREATE TABLE [dbo].[scall](
[process] [varchar](50) NULL,
[period] [varchar](8) NULL,
[ClientID] [bigint] NULL,
[CallID] [bigint] NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[call](
[period] [varchar](8) NULL,
[CallID] [bigint] NULL,
[Mem] [bigint] NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[usr](
[process] [varchar](50) NULL,
[ClientID] [bigint] NULL,
[Usr] [varchar](255) NULL
) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_PC] ON [dbo].[call]
(
[period] ASC,
[CallID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_PC] ON [dbo].[scall]
(
[period] ASC,
[CallID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_CP] ON [dbo].[usr]
(
[ClientID] ASC,
[process] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
Затем, в эти таблицы необходимо загрузить данные из соответствующих csv файлов. Сделать это можно с помощью SQL Server Integration Services
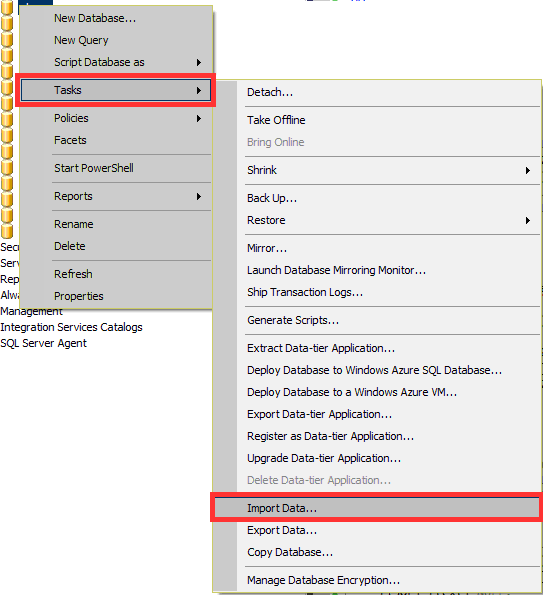
После того, как информация будет загружена в таблицы, можно проводить анализ.
TOP – 10 пользователей в разрезе процессов и времени
Копировать в буфер обменаSELECT TOP 10
s.[process],
s.[period],
s.[ClientID],
u.[Usr],
SUM(c.[Mem]) AS Mem
FROM
[dbo].[call] AS c
INNER JOIN [dbo].[scall] AS s
ON s.[period] = c.[period]
AND s.CallID = c.CallID
LEFT OUTER JOIN (SELECT DISTINCT process, ClientID, [Usr] FROM [dbo].[usr]) AS u
ON u.process = s.process
AND u.ClientID = s.ClientID
GROUP BY
s.[process],
s.[period],
s.[ClientID],
u.[Usr]
ORDER BY
Mem Desc
Запрос покажет топ-10 пользователей, которые поместили больше всего сеансовых данных в час. Затем необходимо разобраться с самым верхним (в текущем случае):
Копировать в буфер обменаrphost_1352 | 15063011 | 518 | Пользователь | 2046616858
Т.е. в процессе rphost_1352 за час с 11-00 по 12-00 пользователь с идентификатором 518 записал в сеансовые данные 2 046 616 858 байт (2Гб).
Далее, необходимо найти все идентификаторы вызовов, которые записывал сеанс 518:
Копировать в буфер обменаSELECT
s.[process],
s.[period],
s.[ClientID],
c.[Mem],
c.CallID
FROM
[dbo].[call] AS c
INNER JOIN [dbo].[scall] AS s
ON s.[period] = c.[period]
AND s.CallID = c.CallID
AND s.[period] = '15063011'
AND s.[ClientID] = 518
AND s.[process] = 'rphost_1352'
ORDER BY
[Mem] DESC
Получится таблица вида:
|
N |
Процесс |
Час |
ID клиента |
Мб |
CallID |
|---|---|---|---|---|---|
|
1 |
rphost_1352 |
15063011 |
518 |
17636477 |
469523160 |
|
2 |
rphost_1352 |
15063011 |
518 |
17636477 |
469524462 |
|
|
… |
… |
… |
… |
… |
|
116 |
rphost_1352 |
15063011 |
518 |
17636477 |
469529999 |
Затем, необходимо открыть файл технологического журнала:
…/rphost_1352/15063011.log
Найти строку: CallID=469523160.
Будет строка вида:
Копировать в буфер обмена59:55.564071-3297021,SCALL,2,process=rphost,p:processName=DB,t:clientID=518,t:applicationName=1CV8,t:computerName=TSERVER,t:connectID=5427,SessionID=32203,Usr=Пользователь,AppID=1CV8,
ClientID=635,Interface=90b77326-8e4a-4195-b980-d758277d1f03,Method=9,CallID=469523160
Затем вверх, от этой строки, ищутся строки с текстом "t:clientID=518". По ним делается вывод о том, что в данный момент делал пользователь.
Копировать в буфер обмена59:52.158136-2,SCALL,2,process=rphost,p:processName=DB,t:clientID=518,t:applicationName=1CV8,t:computerName=TSERVER,t:connectID=5427,SessionID=32203,Usr=Пользователь,AppID=1CV8,ClientID=635,
Interface=90b77326-8e4a-4195-b980-d758277d1f03,Method=13,CallID=469523137,Context='Форма.Вызов : Обработка.Загрузка.Форма.ФормаСписка.Модуль.Записать
Обработка.Загрузка.Форма.ФормаСписка.Форма : 777 : Объект=Ссылка.ПолучитьОбъект();'
Т.е. при каждом вызове Обработка.Загрузка.Форма.ФормаСписка.Форма : 777 : Объект =Ссылка.ПолучитьОбъект();' в сеансовые данные пишутся 17 636 477 байт. Таких вызовов 116.
Итого: 17636477 * 116 = 2 Гб.
Максимальный размер сеансовых данных за один вызов
Копировать в буфер обменаSELECT TOP 10
period,
CallID,
Mem
FROM
[dbo].[call]
ORDER BY
Mem Desc
Запрос возвращает TOP-10 вызовов с самым большим размером сеансовых данных.
Например, первой будет строка:
15063011 | -698296315 | 1496373044 ~ (1,4 Гб)
По этой строке ищется процесс и ID клиента.
Копировать в буфер обменаSELECT
process,
period,
ClientID,
CallID
FROM
[dbo].[scall]
WHERE
[period]= '15063011'
AND [CallID] = -698296315
Получим запись:
rphost_1352 | 15063011 | 493 | -698296315
В файле …/rphost_1352/15063011.log ищется строчка с CallID=-698296469
Копировать в буфер обмена37:59.941001-1,SCALL,2,process=rphost,p:processName=DB,t:clientID=493,t:applicationName=1CV8,t:computerName=TSERVER,t:connectID=19263,SessionID=57012,Usr=Пользователь,ClientID=788,
Interface=90b77326-8e4a-4195-b980-d758277d1f03,Method=12,CallID=-698296469,Context='Система.ПолучитьФорму : Отчет.КарточкаСчета.Форма.ФормаОтчета
Отчет.КарточкаСчета.Форма.ФормаОтчета.Форма : 777 : БухгалтерскиеОтчетыВызовСервера.ПриСозданииНаСервере(ЭтаФорма, Отказ, СтандартнаяОбработка);
ОбщийМодуль.БухгалтерскиеОтчетыВызовСервера.Модуль : 888 : Форма.СформироватьОтчетНаСервере();
Отчет.КарточкаСчета.Форма.ФормаОтчета.Форма : 999 : БухгалтерскиеОтчетыВызовСервера.СформироватьОтчет(ПараметрыОтчета, АдресХранилища);
ОбщийМодуль.БухгалтерскиеОтчетыВызовСервера.Модуль : 111 : ПоместитьВоВременноеХранилище(Новый Структура("Результат,ДанныеРасшифровки", Результат, ДанныеРасшифровки), АдресХранилища);'
Таким образом, видно, что пытаясь сформировать отчет "Карточка счета", пользователь задал неоптимальные отборы и отчет поместил во временное хранилище 1496373044 байт (1,4 Гб).