07.12.2015
Перед началом работ по оптимизации системы необходимо всегда получать начальную оценку производительности при помощи "Оценки интегральной производительности системы по методике APDEX".
Если по данным Apdex видим, что существуют такие ключевые операции, оценка производительности которых "Неприемлемо", "Очень плохо" или "Плохо", то необходимо выполнять работы по оптимизации таких операций в порядке их приоритетов.
Первым шагом при выполнении работ по оптимизации выбранной ключевой операции будет анализ сырых данных Apdex. Для корректного анализа число замеров должно быть значительным, например, больше 100.
По сырым данным Apdex нужно понять:
Если в полученном распределении имеется несколько пиков, то нужно понять:
Получим распределение времени выполнения операции.
Для этого необходимо воспользоваться обработкой "Оценка производительности", которая входит в состав одноименной подсистемы БСП и в ЦКК (Центр контроля качества, входит в состав Корпоративного инструментального пакета).
С помощью встроенной обработки "Оценка производительности" (её можно найти в настройках контрольной процедуры "Контроль производительности") существует возможность получать распределение времени выполнения одной или нескольких ключевых операций за любой период времени.
Как обработка получает распределение времени? Выбираются необходимые данные замеров времени по ключевой операции за интересующий нас период времени из регистра сведений ЗамерыВремени.
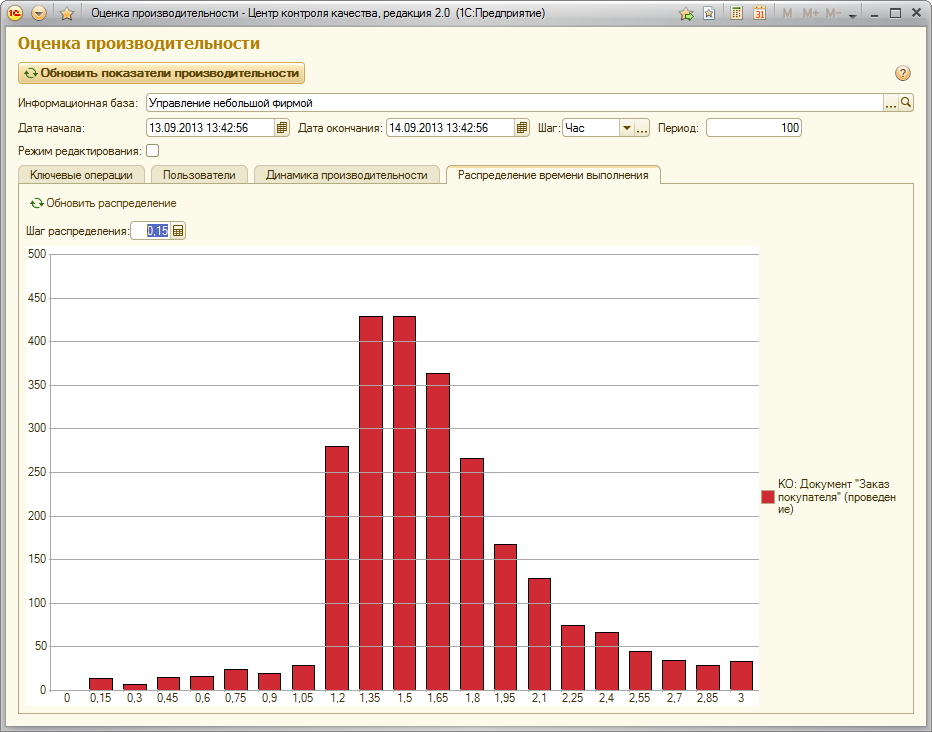
Рассмотрим, для примера ключевую операцию "Проведение документа "Заказ покупателя"".
Выберем длительность периода 1 секунда, и разобьём все значения замеров времени по периодам, например от 0 до 6 секунд. Каждый следующий замер времени из сырых данных Apdex будет отнесен к своему периоду. Например, замер операции, которая выполнилась за 1,51 секунды, будет отнесен к периоду от 1 до 2 (т.е. к периоду (1,2], или просто 2). Если операция выполнилась за 1 секунду, то её замер будет отнесен к периоду от 0 до 1 (т.е. к периоду (0,1], или просто 1). Когда определен период, к которому относится выбранный замер, счетчик числа замеров этого периода увеличивается на 1.
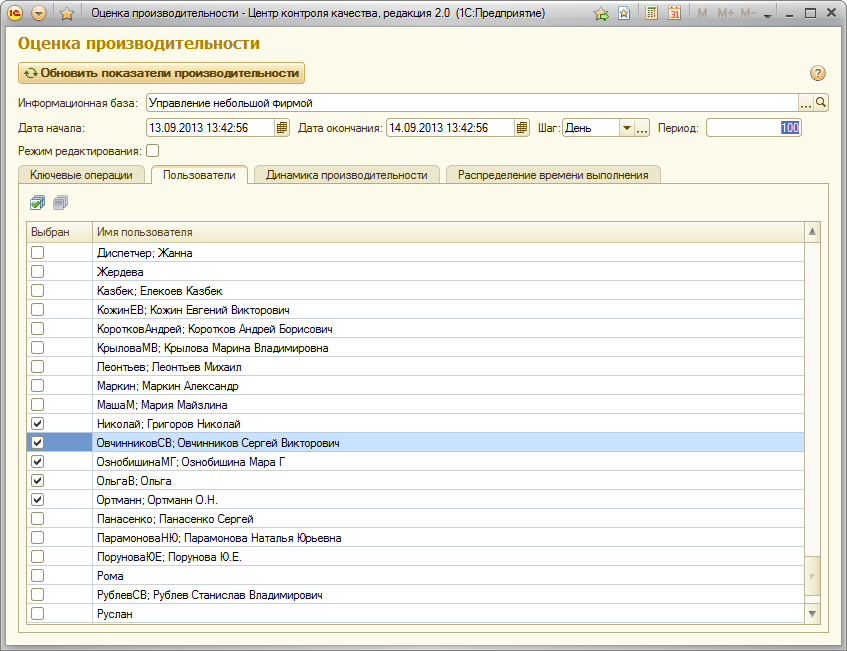
Также в обработке "Оценка производительности" существует возможность выбирать пользователей, по которых необходимо получить оценку производительности за выбранный период времени
В результате по данным замеров времени получаем следующее распределение времени выполнения операции.
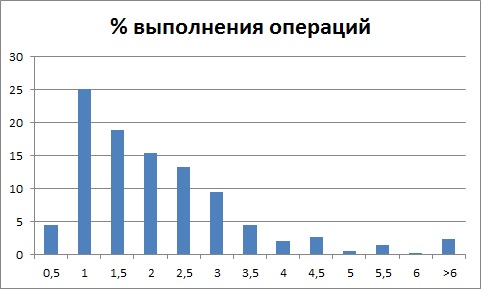
Видим распределение времени выполнения операции с одним пиком.
Если время выполнения выглядит так:
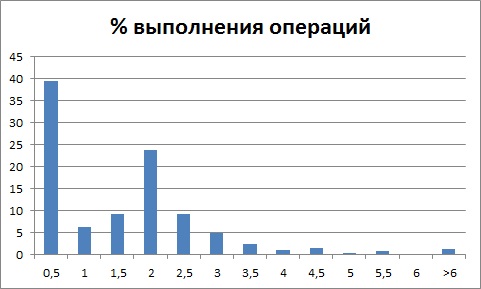
то это говорит о неверно встроенных счетчиках замеров времени. Мы наблюдаем два пика, при этом первый из них меньше 0,5 секунды.
Такое распределение характерно для замеров проведения документов, которые начинаются, но не завершаются корректно из-за какой-либо ошибки выполнения операции.
Если время выполнения выглядит так:
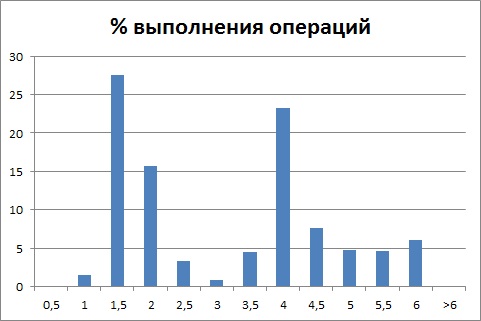
т.е. распределение имеет несколько отчетливо выраженных пиков (которые не находятся в окрестности 0 секунд), то это говорит о том, что в рамках одной ключевой операции выполняется несколько различных по продолжительности операций, а распределение времени выполнения которых по отдельности будет выглядеть так:
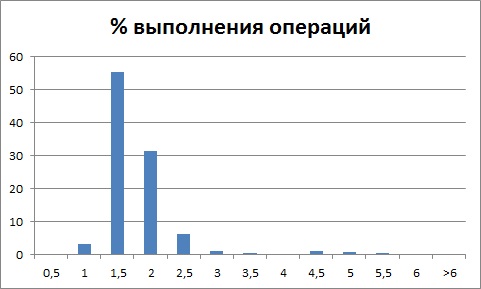
и так:
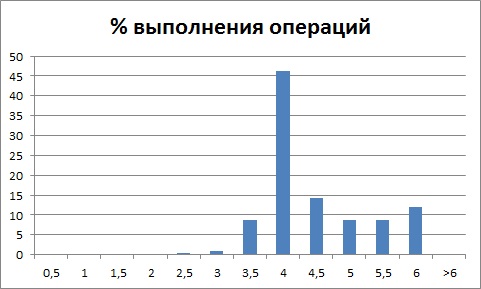
В результате анализа распределения времени выполнения операции, видим за какое время чаще всего выполняется операция.
Следующим шагом нужно будет попытаться воспроизвести время выполнения операции, которое:
Если пиков было несколько, необходимо научиться воспроизводить каждый из пиков. Анализ выполнения ключевой операции нужно провести для каждого пика отдельно.
Необходимо правильно воспроизводить медленное выполнение операции.
Нужно:
НЕ нужно:
Вы можете получить два результата:
При воспроизведении медленного выполнения операции необходимо всегда замерять время выполнения операции по секундомеру.
Очень важно понимать, какую именно операцию нужно воспроизвести. Мы не просто так искали пик распределения времени.
Мы его искали для того, чтобы потом найти операцию, которая попадает в этот пик, и выполнять именно её.
Необходимо всё делать на том же оборудовании. Желательно воспроизводить ровно в тех же самых условиях, конечно, не всегда это возможно.
При воспроизведении необходимо постараться получить условия, в которых операция выполняться быстро, медленно.
Например, пользователь в рабочей системе наиболее часто выполняет операцию за время, близкое к 4 секундам. А целевое время операции T = 1,5 секунды.
Если выполнять операцию в рабочее время, то мы "попадаем в пик", если выполнять операцию в нерабочее время, то мы воспроизводим 1,8 секунды.
Тут очень важно остановить, нарисовать линию, на которой отсечками указать, на что именно уходит время. Если этого не сделать, то можно принять неверное решение.
Неверное решение:
Удалось воспроизвести 1,8 секунды, что больше целевого времени на 0,3 секунды. Это означает, что мы воспроизвели медленное выполнение операции. Если все пользователи будут выполнять операцию ровно за это время, то Apdex будет в районе 0,5. Отлично, дальше разбираемся с тем, на что уходит время. Видим, что практически 1 секунда уходит на выполнение запросов сервером СУБД. Понимаем, что 56% времени (больше половины) уходит в СУБД, оптимизируем неоптимальные запросы. В результате в лучшем случае максимум распределения в рабочей системе сдвигается с 4 секунд до 3 секунд. Производительность недостаточная. Проблема не решена. Проверяем, как выполняется операция в рабочее и в нерабочее время. Понимаем, что большая часть времени (а именно, 2,2 секунды) уходит куда-то именно под нагрузкой. Т.е. основная проблема тут очередь! Где именно, мы пока не знаем.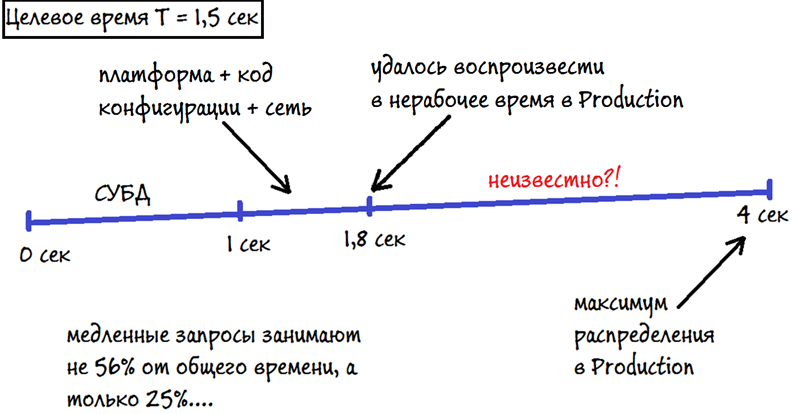
Далее, по очереди смотрим:
Если операция чаще всего выполняется в веб клиенте, нужно обязательно проверить скорость её выполнения в тонком клиенте и в различных браузерах.
Основной задачей будет: понять, НА ЧТО уходит большая часть времени выполнения операции.
В первую очередь предлагается получить:
Получать все выше перечисленные данные нужно от 1, 2 и 3 выполнения ключевой операции. Первое выполнение должно быть несколько дольше второго и третьего выполнения операции.
Для того чтобы правильно получить замер конфигуратором с серверной частью, нужно чтобы:
Более детально этот вопрос отражен в статье Отладка прикладных решений
Время выполнения всех запросов в однопользовательском режиме от одного выполнения операции можно получить, пользуясь:
Рассмотрим, как можно получить суммарное время выполнения всех запросов на примере MS SQL Server.
Для этого требуется собрать трассировку с помощью MS SQL Profiler по следующим классам событий от одного выполнения операции:
У перечисленных классов событий обязательно должны собираться данные по полю Duration, т.к. данные по этому полю необходимо будет проанализировать в первую очередь.
Рекомендуется всегда устанавливать фильтр по полям DatabaseName и/или DatabaseID.
DatabaseID можно получить, выполнив запрос:
Копировать в буфер обменаDB_ID ( [ 'database_name' ] )
О том, как фильтровать события в трассировке, есть статья от Microsoft.
Трассировку от одного выполнения операции нужно сохранить в выбранную вами (любую, но НЕ рабочую базу) базу данных, как таблицу, назовем её trace_table_1.
Войдите в выбранную вами базу с помощью MS Server Management Studio и выполните запрос:
Копировать в буфер обменаSELECT SUM([Duration])/1000 AS ms, SUM([Duration])/1000000 AS sec FROM [db].[dbo].[trace_table_1]
Достоинство такого подхода:
Недостатки:
Рассмотрим, как можно получить суммарное время выполнения всех запросов с помощью технологического журнала.
Для этого сначала подготовим файл logcgf.xml.
Копировать в буфер обмена<?xml version="1.0" encoding="UTF-8"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<dump create="true" location="C:\DUMPS" type="3" prntscrn="false"/>
<log location="C:\LOGS\KO1" history="48">
<event>
<eq property="Name" value="DBMSSQL"/>
<like property="p:processName" value="%db%"/>
</event>
<property name="all"/>
</log>
<plansql/>
</config>
Событие DBMSSQL позволит собрать все SQL запросы технологической платформы 1С к СУБД MS SQL Server с фильтром по одной базе db.
<plansql/> позволит сразу же получить планы запросов, что позволит проанализировать причину неоптимального выполнения запросов (если, конечно, проблема будет именно в них).
Внимание! При работе с СУБД Oracle НЕ нужно собирать планы при сборе технологического журнала, т.к. это приведет к значительному замедлению работы системы в целом.
Такой файл необходимо расположить на сервере в директории "\bin\conf".
В ОС Windows для технологической платформы версии 8.2.18.101 путь к расположению этого файла будет выглядеть так:
"C:\Program Files\1cv82\8.2.18.101\bin\conf".
Необходимо до копирования файла logcfg.xml в указанную директорию подготовиться выполнить ключевую операцию.
Это нужно сделать для того, чтобы в собранный технологический журнал в директорию "C:\LOGS\KO1" не попали никакие другие запросы, которые не относятся к ключевой операции.
После того, как вы скопировали файл logcfg.xml с нужными настройками в "\bin\conf" нужно подождать 1 минуту и НЕ выполнять никаких действий.
Дело в том, что платформа читает файл logcfg.xml один раз в минуту, поэтому необходимо подождать и убедиться, что журнал начал собираться с нужными нам настройками.
Выполните операцию один раз и получите от ОДНОГО выполнения ключевой операции:
В собранном технологическом журнале нужно посчитать сумму длительностей всех запросов. Для этого, нужно найти в нем все события DBMSSQL. Пример такого события приведен ниже:
Копировать в буфер обмена50:21.1251-12,DBMSSQL,5,process=rphost,p:processName=db,t:clientID=92,t:applicationName= 1CV8,t:computerName=TERM1,t:connectID=1887,SessionID=20321,Usr=Анна,Trans=1,dbpid=61,Sql='SELECT T1._Version FROM _Reference85 T1 WHERE T1._IDRRef = ? p_0: 0xB8DC002590380BA011E1E1FAC99ECB37 ',Rows=1,RowsAffected=-1,planSQLText=' 1, 1, 1, 0.00313, 0.000158, 15, 0.00328, 1, |--Clustered Index Seek(OBJECT:([upo].[dbo].[_Reference85].[PK___Referen__AC8ED0C43434DA15] AS [T1]), SEEK:([T1].[_IDRRef]=[@P1]) ORDERED FORWARD) '
В этом событии DBMSSQL мы видим, что пользователь от имени "Анна" выполнил запрос в базе "db", который завершился в 50 минут 21,1251 секунду и длился 0,012 секунды.
На данном этапе нас интересуют не конкретные запросы и их планы, а общее время выполнения всех запросов. Очень важно понять: на ЧТО уходит время выполнения операции.
Нужно ответить на вопросы:
Время, которое работал код платформы на языке 1С, который относится к данной ключевой операции, можно увидеть, нажав Ctlr + A в замере конфигуратором.
Время работы платформенных вызовов = время выполнения операции (по секундомеру) - время выполнения кода платформы на языке 1С.
Только после того, когда будет совершенно точно известно, на что уходит больше всего времени, нужно расследовать, почему это происходит.
Важно в первую очередь заниматься именно тем, что даст наибольший эффект от оптимизации ключевой операции.
Не всегда это будет техническая оптимизация, может быть, сразу станет ясно, что операция выполняется неоптимально с методической точки зрения. Этот факт также необходимо учитывать.
Бывают ситуации, когда время равномерно "размазано" по нескольким отрезкам, то есть, явного лидера не видно. Такое возможно как в самом начале, так и на поздних этапах оптимизации операции, когда все явные проблемы были уже устранены.
В этом случае стоит рассмотреть архитектурные способы оптимизации. Например:
Предложенная методика также работает в случаях, когда необходимо оптимизировать очень сложную операцию или запрос.
Например, долго выполняется обновление динамического списка, в котором имеется очень сложный запрос на получение данных о реализациях товаров и информации о контрагентах.
Если в однопользовательском режиме не воспроизводится медленное выполнение операции, нужно:
Одной из наиболее частых причин, из-за которой не воспроизводится медленное выполнение операции, является наличие очереди к ресурсам. Симптомом этой проблемы будет тот факт, что операция выполняется быстро именно в однопользовательском режиме, а в рабочее время скорость выполнения операции значительно ниже.
В ЦКК в подсистеме Мониторинга также возможно добавить один или несколько показателей производительности Apdex
Возможно вывести на это же график (или на отдельный график в режиме "Анализ показателей") время выполнения выбранной ключевой операции (в секундах).
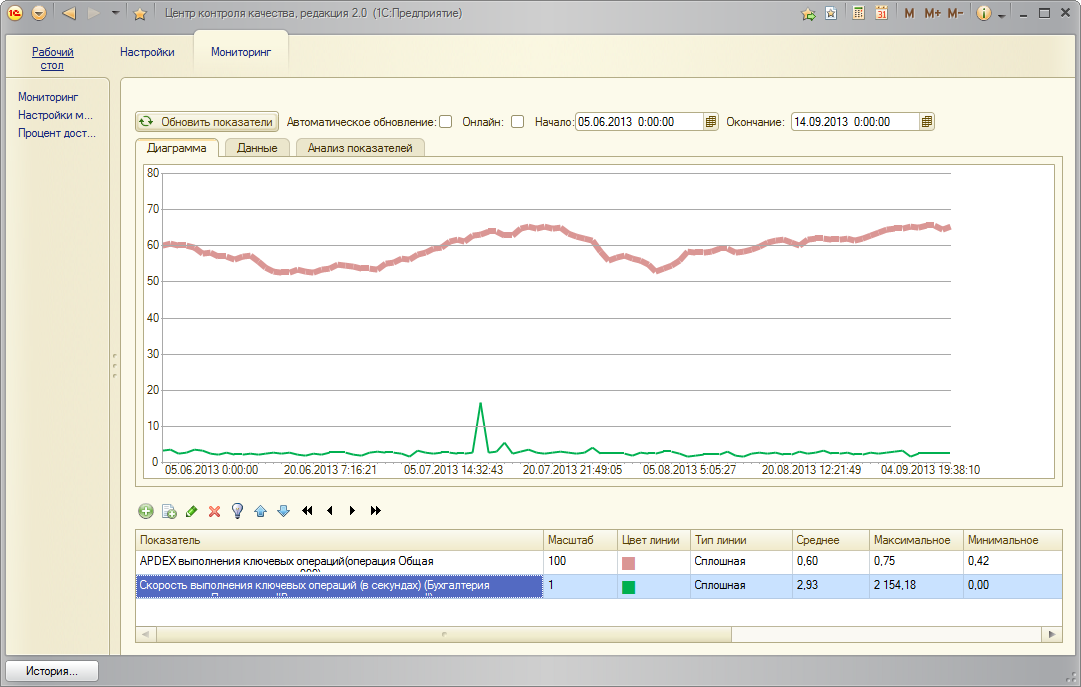
По данным мониторинга можно оперативно среагировать на изменения производительности в системе по одной или нескольким операциям.
По графику можно выявить корреляцию изменения производительности с другими факторами, например, числом пользователей, одновременно работающих в системе.
Причиной такой корреляции могут быть очереди на оборудовании. Для того чтобы их исключить, необходимо проанализировать загруженность оборудования на рабочих серверах "1С:Предприятия" и сервере СУБД.
Часто наиболее узким местом становится именно дисковая подсистема на серверах СУБД. Тут важно не торопиться и не принимать сразу решение о покупке дорогостоящего хранилища. Ситуацию можно значительно улучшить за меньшие деньги. Для этого понадобится понять, а какие именно запросы создают наибольшую нагрузку на дисковую подсистему сервера СУБД. В результате выявления наиболее узких мест, необходимо будет решать, как их устранить.
Также среди причин могут быть избыточные ожидания на блокировках. Для расследования этой проблемы необходимо подключить ЦУП и собрать аналитику по ожиданиям на блокировках за 15 минут работы системы.
По собранной аналитике нужно расследовать, возникают ли избыточные ожидания на блокировках в момент выполнения ключевой операции.
Иногда возникает вопрос: как найти запросы, которые создают наибольшую нагрузку на диск. Для этих целей не правильно использовать ЦУП, особенно, если нагрузка на систему высокая. ЦУП получает информацию из технологического журнала, который станет узким местом в производительности системы (вместе с дисковой подсистемой, которая будет для этого использоваться) на время сбора полной аналитики (без фильтров по Длительности (Duration)) по запросам.
Ниже приведена методика на примере MS SQL Server. Если у вас используется другая СУБД, то смысл методики не меняется, изменится только инструмент.
1. Настройте MS SQL Profiler по классам событий
Для выбранных классов событий оставьте поля
Установите фильтры по DatabaseID (на исследуемую базу), Reads > N, где N может меняться от 1000000 до 10000. Начните с 1000000. В следующих трассировках можете уменьшить это число. Ваша трассировка должна быть достаточного объема, чтобы делать по ней выводы.
2. Соберите трассировку в пике нагрузки на систему в течение нескольких минут.
3. Сохраните трассировку в отдельную базу данных как таблицу.
4. Сгруппируйте все запросы по TextData, посчитав сумму Reads. Посчитайте суммарное число логических чтений, которое создает какой-либо запрос. В результате вы найдете один или несколько запросов, которые создают наибольшую нагрузку на чтение.
5. Теперь остается найти самый тяжелый (или несколько тяжелых) по числу чтений запрос в коде конфигурации. Например, можно настроить технологический журнал с фильтрами только на один запрос. Может выглядеть так:
Копировать в буфер обмена<?xml version="1.0" encoding="UTF-8"?>
<config xmlns=" v8.1c.ru/v8/tech-log »»">
<log location="С:\Sql_Reads" history="2">
<event>
<eq property="Name" value="DBMSSQL"/>
<like property="Sql" value="%Reference5774%"/>
<like property="Sql" value="%SELECT TOP%"/>
</event>
<property name="all"/>
</log>
<plansql/>
</config>
Смысл в том, чтобы указать такие фильтры:
Копировать в буфер обмена<like property="Sql" value="%Reference5774%"/>
которые будут включать имена таблиц в найденном вами на предыдущем шаге запросе. Если всё аккуратно сделаете, то в полученном технологическом журнале запрос у вас будет только тот, который нужен. Журнал получится небольшим.
6. Проанализируйте план запроса, частоту выполнения запроса.
При выполнении этих шагов может оказаться, что запросов таких немного, и они имеют неоптимальные планы. Может оказаться, что есть методические ошибки, например, запросы в цикле. Вы их увидите, сделав группировку по тексту запроса. В этом случае также придется исправлять в коде конфигурации. Группируя тексты запросов, вы можете понять, что на самом деле, большая часть тяжелых запросов строится "вокруг" одного или нескольких таблиц. В этом случае стоит подумать о построении промежуточных технологических таблиц, которые будут хранить посчитанные значения. Используйте механизмы платформы (например, агрегаты) там, где это возможно.Если вы используете именно MS SQL Server, то имеет смысл для решения этой задачи использовать динамические административные представления. Тогда необходимую информацию можно получить, выполнив скрипт:
Копировать в буфер обменаCREATE DATABASE dm_dump_query_and_file_stats;;GO
USE dm_dump_query_and_file_stats;
GO
SELECT *
INTO db
FROM sys.databases;
GO
SELECT *
INTO io_virtual_file_stats
FROM sys.dm_io_virtual_file_stats(NULL, NULL);
GO
SELECT cp.*, st.dbid, qp.query_plan, st.text
INTO exec_cached_plans
FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) qp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st;
GO
SELECT qs.*, st.dbid, qp.query_plan, st.text
INTO exec_query_stats
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st;
GO
USE master;